FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Problem
Framing
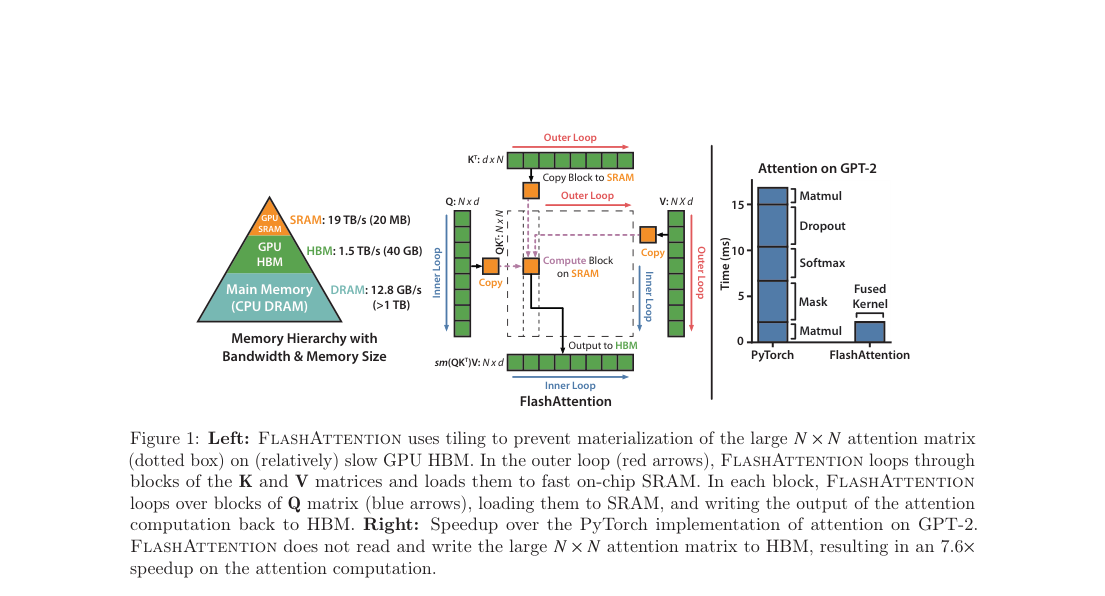
Standard exact attention is IO-bound: it materializes the score matrix in HBM, so memory traffic dominates long-context runtime and memory. FlashAttention closes this gap with SRAM-resident tiling and online softmax, preserving exact attention while reducing HBM accesses to instead of .
Currently Used Methods
Foundational
- @vaswaniAttentionAllNeed2017 — exact scaled dot-product attention over dense .
- Limitation in context: writes the full score matrix to HBM, causing quadratic memory traffic.
Proposed Method
Architecture
FlashAttention preserves exact self-attention and only changes execution order. It tiles , , and into SRAM blocks, fuses score, masking, softmax, dropout, and value accumulation, and writes only output tiles to HBM.
Loss / Objective
The operator is unchanged from standard exact attention:
Algorithm
Its key step is an online softmax merge across key-value tiles, so prior score blocks are never materialized:
Training Procedure
- SRAM budget in analysis: bytes.
- Tile sizes: , .
- BERT-large: batch size , LAMB, learning rate , at most steps.
- GPT-2: effective batch size , AdamW, learning rate small, medium.
Evaluation
Datasets
- Wikipedia for BERT-large pretraining.
- OpenWebText for GPT-2 small and medium.
- Long Range Arena: ListOps, Text, Retrieval, Image, Pathfinder.
- MIMIC-III long-document classification.
- ECtHR long-document classification.
- Path-X and Path-256 long-context reasoning.
Metrics
- Training time.
- Speedup over baseline implementations.
- OpenWebText perplexity.
- Accuracy on LRA and Path tasks.
- Micro- on long-document classification.
- Attention runtime and memory footprint.
Headline results
- BERT-large: min vs , faster.
- GPT-2 small: ppl , days, over HuggingFace.
- GPT-2 medium: ppl , days, over HuggingFace.
- GPT-2 small, context: ppl , still over Megatron .
- Path-X / Path-256: / accuracy.
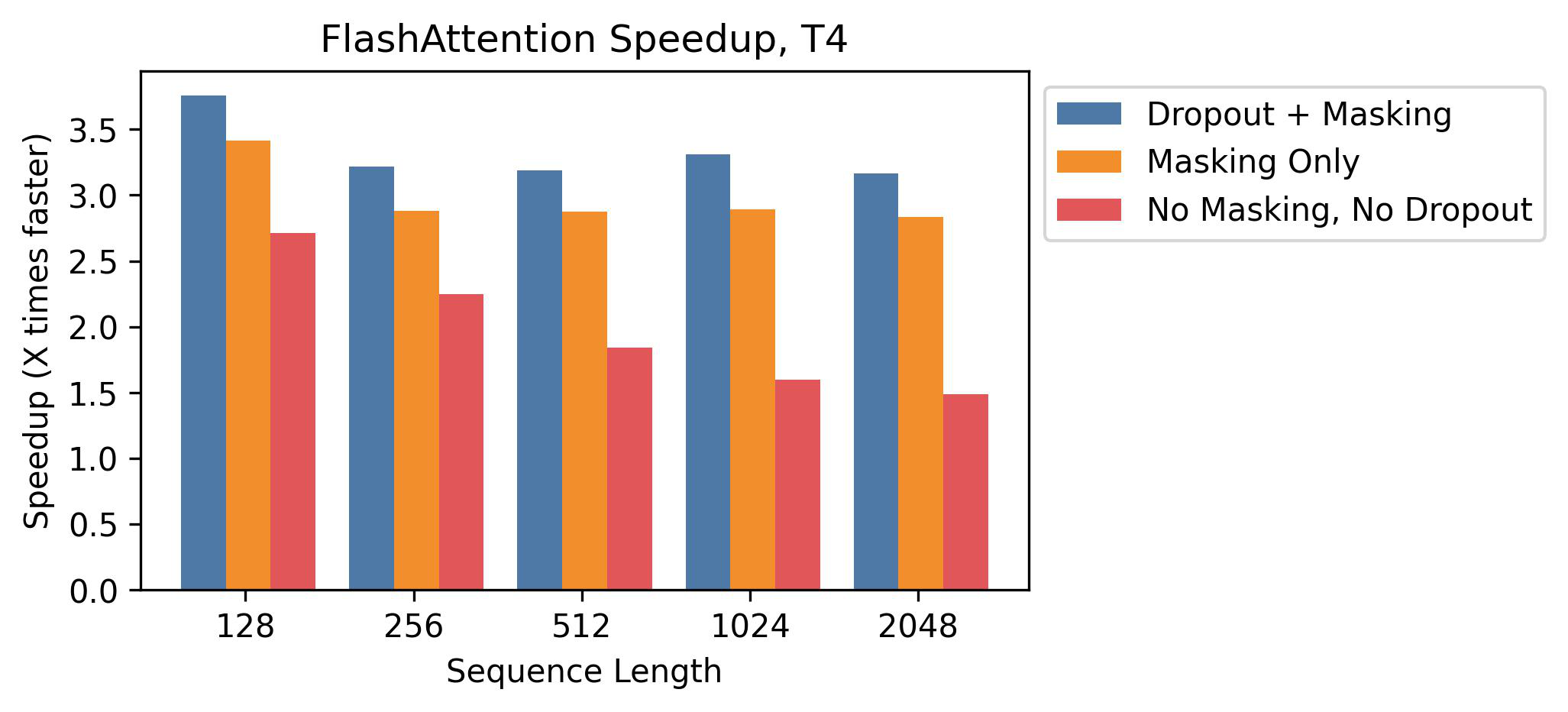
Table 3: Long-Range Arena accuracy and speedup
| Models | ListOps | Text | Retrieval | Image | Pathfinder | Avg | Speedup |
|---|---|---|---|---|---|---|---|
| Transformer | 36.0 | 63.6 | 81.6 | 42.3 | 72.7 | 59.3 | - |
| FlashAttention | 37.6 | 63.9 | 81.4 | 43.5 | 72.7 | 59.8 | 2.4× |
| Block-sparse FlashAttention | 37.0 | 63.0 | 81.3 | 43.6 | 73.3 | 59.6 | 2.8× |
| Linformer [84] | 35.6 | 55.9 | 77.7 | 37.8 | 67.6 | 54.9 | 2.5× |
| Linear Attention [50] | 38.8 | 63.2 | 80.7 | 42.6 | 72.5 | 59.6 | 2.3× |
| Performer [12] | 36.8 | 63.6 | 82.2 | 42.1 | 69.9 | 58.9 | 1.8× |
| Local Attention [80] | 36.1 | 60.2 | 76.7 | 40.6 | 66.6 | 56.0 | 1.7× |
| Reformer [51] | 36.5 | 63.8 | 78.5 | 39.6 | 69.4 | 57.6 | 1.3× |
| Smyrf [19] | 36.1 | 64.1 | 79.0 | 39.6 | 70.5 | 57.9 | 1.7× |
Ablations
- Sequence length sweep: exact FlashAttention stays faster than standard attention through at least .
- Kernel fusion: masking and dropout increase the measured speedup the most.
- Longer GPT-2 context: improves perplexity from to .
- Long-document context: MIMIC-III rises from at to at .
Method Strengths and Weaknesses
Strengths
- Exact attention semantics, not an approximation.
- Additional memory is beyond inputs and outputs.
- Delivers GPT-2 small training speedup at matched perplexity.
- Enables non-random Path-X and Path-256 Transformer results.
Weaknesses
- Dense compute remains quadratic in sequence length.
- Requires custom CUDA kernels per attention variant.
- Gains depend on GPU SRAM size and memory hierarchy.
- Block-sparse extension needs a chosen sparsity pattern.
Suggestions from the authors
- Compile high-level attention code into IO-aware CUDA kernels.
- Extend IO-aware optimization beyond attention.
- Analyze optimal attention execution across multiple GPUs.
- Generalize block-sparse kernels to broader structured patterns.
Links
Prior Papers
- @vaswaniAttentionAllNeed2017 — introduces dense exact attention, the operator FlashAttention reorders to reduce IO.
Further Papers
No vault papers identified as further work yet.