Attention Is All You Need
Attention Is All You Need
Problem
Framing
RNN and CNN transducers bottleneck on sequential computation, so training scales poorly and long-range paths stay long. The paper replaces both with a pure self-attention encoder-decoder, reaching 28.4 BLEU on WMT14 En-De and 41.8 BLEU on En-Fr.
Currently Used Methods
Foundational
- @sutskeverSeq2Seq2014 — recurrent encoder-decoder sequence transduction.
- Limitation in context: token-by-token state updates block full parallel training.
- @bahdanauAttention2014 — additive alignment attention for neural translation.
- Limitation in context: attention still depends on a recurrent backbone.
- @choGRU2014 — gated recurrent units for sequence modeling.
- Limitation in context: gating preserves sequential dependency across positions.
- @baLayerNormalization2016 — layer normalization for stable deep sequence models.
- Limitation in context: optimization improves, but recurrence remains the bottleneck.
Proposed Method
Architecture
The model stacks 6 encoder and 6 decoder layers. Each encoder layer applies multi-head self-attention and a position-wise FFN; each decoder layer adds masked self-attention and encoder-decoder attention. Base settings are , , , and .
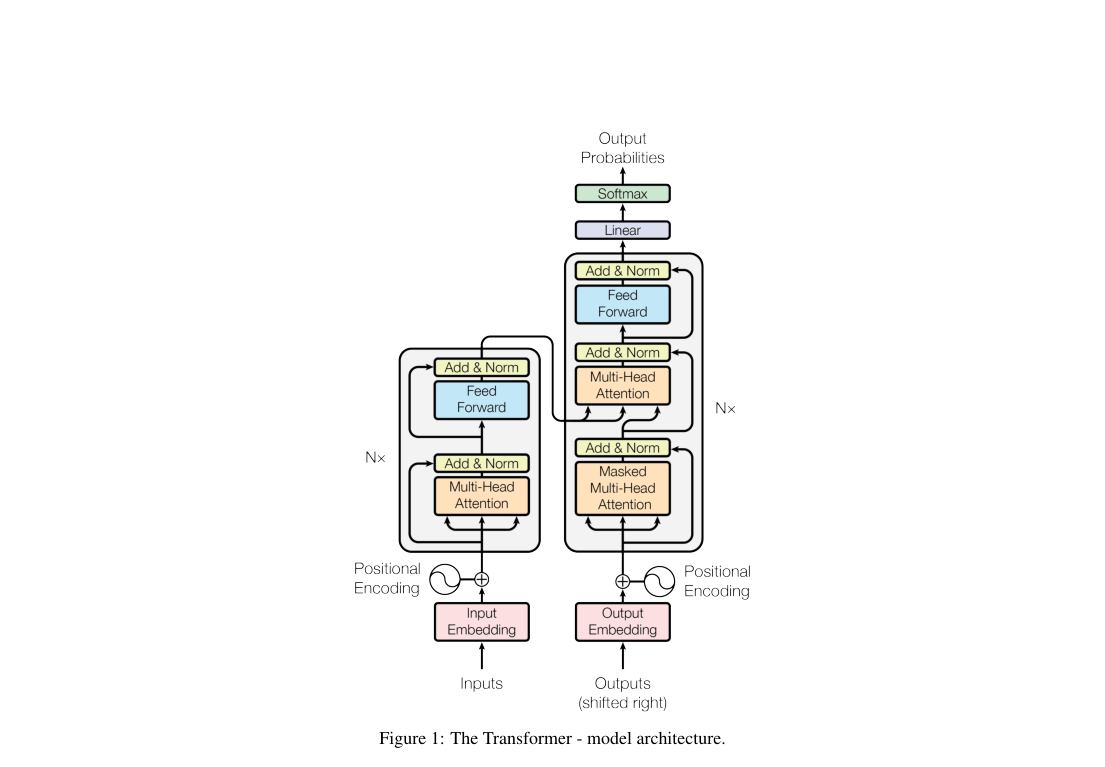
Loss / Objective
Training uses next-token cross-entropy with label smoothing .
Algorithm
The core computation is scaled dot-product attention, composed into multi-head attention.
Training Procedure
- Layers: encoder, decoder.
- Base: , , , .
- Big: , , .
- Optimizer: Adam, , , .
- Learning rate:
- Warmup steps: .
- Dropout: base, big.
- Label smoothing: .
- Training steps: base, big.
- Decoding: beam size , length penalty .
Evaluation
Datasets
- WMT14 English-German: 4.5M sentence pairs.
- WMT14 English-French: 36M sentence pairs.
- WSJ Section 23 constituency parsing.
Metrics
- BLEU for translation.
- Development perplexity.
- WSJ23 F1 for parsing.
- Training cost in FLOPs and wall-clock time.
Headline results
- WMT14 En-De (Transformer big): BLEU 28.4.
- WMT14 En-De (base): BLEU 27.3.
- WMT14 En-Fr (single model): BLEU 41.8.
- WMT14 En-Fr (base): BLEU 38.1.
- WSJ23 parsing: F1 92.7.
Table 1: En-De development ablations over heads, width, dropout, label smoothing, and model size
| Setting | N | dmodel | dff | h | dk | dv | Pdrop | εls | train steps | PPL (dev) | BLEU (dev) | params ×106 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base | 6 | 512 | 2048 | 8 | 64 | 64 | 0.1 | 0.1 | 100K | 4.92 | 25.8 | 65 |
| (A) | 1 | 512 | 512 | 5.29 | 24.9 | |||||||
| (A) | 4 | 128 | 128 | 5.00 | 25.5 | |||||||
| (A) | 16 | 32 | 32 | 4.91 | 25.8 | |||||||
| (A) | 32 | 16 | 16 | 5.01 | 25.4 | |||||||
| (B) | 16 | 5.16 | 25.1 | 58 | ||||||||
| (B) | 32 | 5.01 | 25.4 | 60 | ||||||||
| (C) | 2 | 6.11 | 23.7 | 36 | ||||||||
| (C) | 4 | 5.19 | 25.3 | 50 | ||||||||
| (C) | 8 | 4.88 | 25.5 | 80 | ||||||||
| (C) | 256 | 32 | 32 | 5.75 | 24.5 | 28 | ||||||
| (C) | 1024 | 128 | 128 | 4.66 | 26.0 | 168 | ||||||
| (C) | 1024 | 5.12 | 25.4 | 53 | ||||||||
| (C) | 4096 | 4.75 | 26.2 | 90 | ||||||||
| (D) | 0.0 | 5.77 | 24.6 | |||||||||
| (D) | 0.2 | 4.95 | 25.5 | |||||||||
| (D) | 0.0 | 4.67 | 25.3 | |||||||||
| (D) | 0.2 | 5.47 | 25.7 | |||||||||
| (E) | positional embedding instead of sinusoids | 4.92 | 25.7 | |||||||||
| big | 6 | 1024 | 4096 | 16 | 0.3 | 300K | 4.33 | 26.4 | 213 |
Ablations
- Attention heads: 1 head is 0.9 BLEU below the best multi-head setting.
- Depth: reducing layers from 6 to 2 drops BLEU from 25.8 to 23.7.
- Width: raises BLEU to 26.0; reaches 26.2.
- Regularization: dropout 0.2 helps BLEU; label smoothing 0.2 helps BLEU but hurts perplexity.
Method Strengths and Weaknesses
Strengths
- Pure self-attention beats prior translation systems on both WMT14 benchmarks.
- Base model trains in 12 hours on 8 P100 GPUs.
- Big model surpasses prior En-De results by over 2 BLEU.
- Same architecture transfers to parsing and reaches 92.7 F1.
Weaknesses
- Self-attention cost grows quadratically with sequence length.
- Big model still needs 300K steps and 3.5 days on 8 GPUs.
- Parsing trails the best reported generative parser, 92.7 versus 93.3 F1.
- Positional design shows little separation between sinusoidal and learned embeddings.
Suggestions from the authors
- Reduce attention cost with restricted neighborhoods for long sequences.
- Extend self-attention models to images, audio, and video.
- Test pure attention on more sequence transduction tasks.
- Study stronger positional representations for order-sensitive settings.
Links
Prior Papers
- @bahdanauAttention2014 — additive attention is the direct precursor Transformer internalizes without recurrence.
- @sutskeverSeq2Seq2014 — establishes the encoder-decoder translation template that Transformer parallelizes.
- @choGRU2014 — represents the recurrent family displaced by self-attention sequence modeling.
- @baLayerNormalization2016 — supplies the normalization primitive used in each residual sublayer.
Further Papers
- @devlinBERT2018 — builds large-scale bidirectional language pretraining on the Transformer encoder.
- @radfordGPT2018 — turns the Transformer decoder into a generative language model.
- @radfordGPT2_2019 — scales decoder-only Transformer language modeling to stronger zero-shot transfer.
- @brownGPT3_2020 — extends the same autoregressive Transformer recipe to massive scale.
- @raffelT5_2020 — recasts NLP tasks into a unified Transformer text-to-text framework.
- @dosovitskiyViT2020 — ports Transformer blocks from text sequences to image patches.
- @rameshDALLE2021 — uses Transformer sequence modeling for text-conditional image generation.
- @daoFlashAttention2022 — targets the quadratic attention bottleneck with a faster exact kernel.
- @huLoRA2021 — adapts large Transformer models with low-rank parameter updates.
- @kaplanScalingLaws2020 — analyzes performance scaling behavior in large Transformer language models.