Language Models are Few-Shot Learners
Language Models are Few-Shot Learners
Problem
Framing
Fine-tuned NLP systems still need labeled task-specific updates, and prompt-only transfer trails badly on benchmarks such as Natural Questions and CoQA. The paper argues that scale alone induces in-context learning in autoregressive transformers, with a 175B model reaching 71.2 on closed-book TriviaQA and 85.0 F1 on CoQA without gradient updates.
Currently Used Methods
Foundational
- @radfordGPT2_2019 — decoder-only autoregressive transformer pre-training with prompt-based adaptation.
- Limitation in context: prompting stayed well below fine-tuned leaders.
- @vaswaniAttentionAllNeed2017 — transformer self-attention backbone for large-scale sequence modeling.
- Limitation in context: no account of task learning from demonstrations alone.
- @devlinBERT2018 — bidirectional pre-training followed by supervised task-specific fine-tuning.
- Limitation in context: each task still needs labeled updates.
- @raffelT5_2020 — text-to-text transfer with strong fine-tuned benchmark coverage.
- Limitation in context: benchmark gains still depend on supervised adaptation.
- @kaplanScalingLaws2020 — scaling laws for loss versus model size and compute.
- Limitation in context: does not establish few-shot task competence.
Proposed Method
Architecture
GPT-3 keeps the GPT-2 decoder-only transformer and scales it to 175B parameters. The largest model uses 96 layers, , 96 heads, , and a 2048-token context window. It alternates dense and locally banded sparse attention.

Loss / Objective
Training uses standard next-token maximum likelihood.
Algorithm
Task adaptation happens only through conditioning on instructions and demonstrations in the context.
Training Procedure
- Training tokens: 300B.
- Optimizer: Adam, , , .
- Gradient clipping: global norm .
- LR schedule: 375M-token warmup, cosine decay to 10% over 260B tokens.
- 175B batch size: 3.2M tokens.
- 175B learning rate: .
- Data mix: Common Crawl 60%, WebText2 22%, Books1 8%, Books2 8%, Wikipedia 3%.
Evaluation
Datasets
- Cloze and completion: LAMBADA, StoryCloze, HellaSwag.
- Question answering: Natural Questions, WebQuestions, TriviaQA.
- Reading comprehension: CoQA, DROP, QuAC, SQuADv2, RACE.
- Reasoning: Winograd, Winogrande, PIQA, ARC, OpenBookQA.
- Aggregate benchmark: SuperGLUE.
- Synthetic tasks: arithmetic, symbol removal, novel-word usage.
Metrics
- Accuracy.
- F1.
- Perplexity.
- Human preference.
- Human-vs-model discrimination.
Headline results
- LAMBADA few-shot: 86.4 accuracy, 1.92 perplexity.
- TriviaQA closed-book few-shot: 71.2 accuracy.
- CoQA few-shot: 85.0 F1.
- HellaSwag few-shot: 79.3 accuracy.
- Winogrande XL few-shot: 77.7 accuracy.
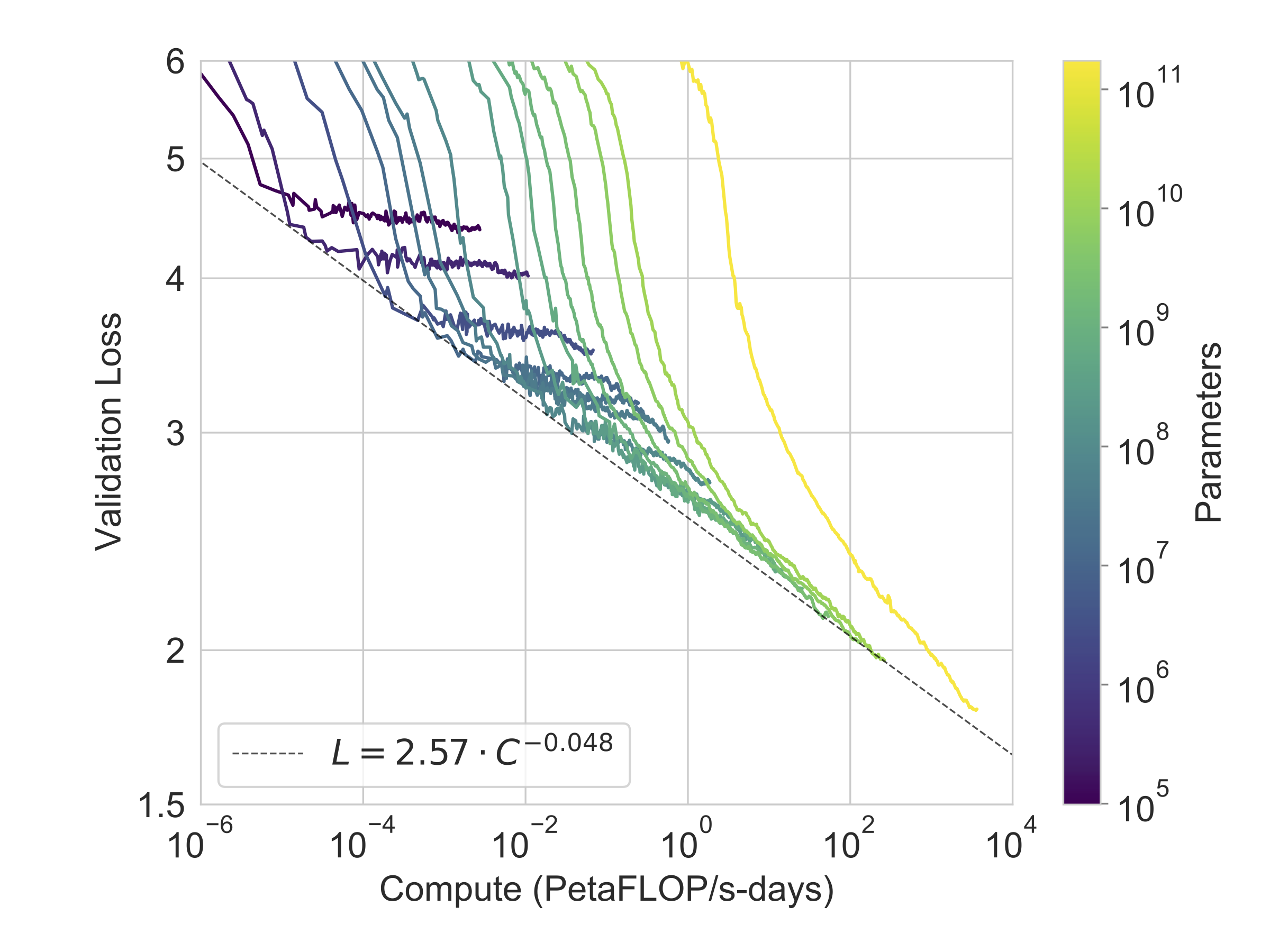
Ablations
- Model size: zero-, one-, and few-shot performance rise smoothly with scale.
- In-context examples : larger contexts improve most tasks, especially for larger models.
- Evaluation regime: few-shot gains widen faster than zero-shot gains as capacity grows.
- Contamination checks: most clean subsets move little, but a few benchmarks remain sensitive.
Method Strengths and Weaknesses
Strengths
- Removes gradient-based task adaptation across many NLP tasks.
- Few-shot gains grow faster than zero-shot gains with scale.
- Closed-book TriviaQA reaches 71.2, competitive with fine-tuned systems.
- Reports contamination analysis instead of only headline scores.
Weaknesses
- Training cost is extreme: 175B parameters and 300B tokens.
- Still weak on RACE, QuAC, DROP, and ANLI.
- Performance depends strongly on prompt format and context budget.
- Web-scale data creates contamination, bias, and misuse risks.
Suggestions from the authors
- Evaluate very large language models under standard fine-tuning.
- Improve performance on adversarial NLI and hard reading comprehension.
- Build stronger methods to detect and reduce benchmark contamination.
- Study bias, misuse, fairness, and energy costs at larger scale.
Links
Prior Papers
- @radfordGPT2_2019 — Direct architectural precursor; GPT-3 mainly scales the GPT-2 decoder-only recipe.
- @vaswaniAttentionAllNeed2017 — Supplies the transformer backbone that GPT-3 scales to 175B parameters.
- @kaplanScalingLaws2020 — Motivates the scaling-law lens used to interpret GPT-3's loss and capability gains.
- @devlinBERT2018 — Represents the fine-tuning paradigm GPT-3 tries to bypass with in-context learning.
- @raffelT5_2020 — Strong text-to-text fine-tuning baseline family contrasted with prompt-only transfer.
- @petersELMo2018 — Earlier contextual pre-training stage before fully task-agnostic transformer transfer.
- @radfordGPT2018 — Establishes generative pre-training as a viable transfer route for NLP tasks.
Further Papers
- @hoffmannChinchilla2022 — Reassesses GPT-3-style scaling and argues for different parameter–data tradeoffs.
- @alayracFlamingo2022 — Extends GPT-3-style in-context learning to multimodal prompting.
- @weiCoT2022 — Builds on large-model prompting to elicit stronger multi-step reasoning.
- @kojimaZeroShotCoT2022 — Shows that prompt design can unlock reasoning without demonstrations.
- @ouyangInstructGPT2022 — Adapts GPT-3-scale models toward instruction following and alignment.
- @huLoRA2021 — Makes adaptation of GPT-3-scale transformers far cheaper through low-rank updates.