Improving Language Understanding by Generative Pre-Training
Improving Language Understanding by Generative Pre-Training
Problem
Framing
Labeled NLU data is scarce, and earlier transfer methods stop at word features or task-specific pipelines. The paper closes this gap with autoregressive pre-training of a decoder-only Transformer, then task-aware fine-tuning with minimal architectural change. It reports state of the art on 9 of 12 benchmarks, including +8.9 on Story Cloze and +5.7 on RACE.
Currently Used Methods
Foundational
- @penningtonGloVe2014 — static word vectors transfer lexical information across tasks.
- Limitation in context: no sentence context or task-conditioned adaptation.
- @petersELMo2018 — contextual language-model features improve downstream NLP.
- Limitation in context: transfer still depends on task-specific architectures.
- @vaswaniAttentionAllNeed2017 — Transformer supplies masked self-attention and long-range conditioning.
- Limitation in context: not yet framed as universal generative pre-training for NLU.
- "Semi-supervised Sequence Learning" — sequence-level LM pre-training improves transfer with recurrent models.
- Limitation in context: weaker long-range memory than the Transformer backbone.
Proposed Method
Architecture
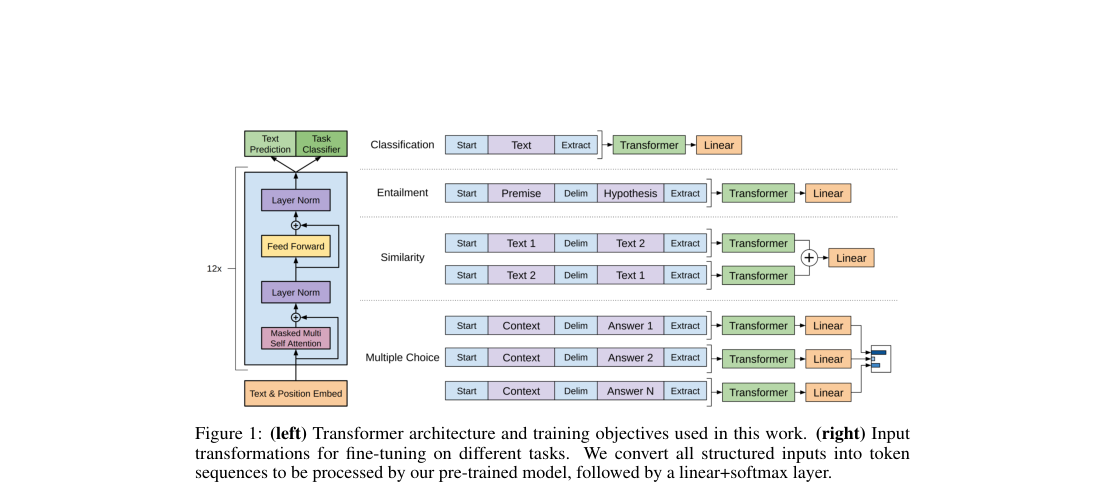
The model is a 12-layer decoder-only Transformer with masked self-attention, hidden size 768, 12 heads, and feed-forward width 3072. Fine-tuning keeps the backbone and serializes each task as one token sequence, then applies a linear classifier to the final token state.
Loss / Objective
Pre-training uses autoregressive likelihood, and fine-tuning adds supervised loss plus an auxiliary LM term.
Algorithm
Each target task is converted to a left-to-right token sequence, and prediction reads out the last hidden state.
Training Procedure
- Pre-training corpus: BooksCorpus, 7,000+ books
- Epochs: 100
- Batch size: 64
- Sequence length: 512
- Optimizer: Adam
- Max learning rate:
- Warmup: 2000 updates
- Learning-rate decay: cosine to 0
- Initialization:
- Vocabulary: BPE, 40,000 merges
- Dropout: 0.1
- Weight decay:
- Activation: GELU
- Fine-tuning learning rate:
- Fine-tuning batch size: 32
- Fine-tuning epochs: 3
- Fine-tuning warmup: 0.2% of training
- Auxiliary LM weight:
Evaluation
Datasets
- Pre-training: BooksCorpus
- NLI: SNLI, MultiNLI, QNLI, RTE, SciTail
- QA and commonsense: RACE, Story Cloze
- Similarity: MRPC, QQP, STS-B
- Classification: SST-2, CoLA
- Aggregate benchmark: GLUE
Metrics
- Accuracy: SNLI, MultiNLI, QNLI, RTE, SciTail, SST-2, RACE, Story Cloze
- F1: MRPC, QQP
- Pearson correlation: STS-B
- Matthews correlation: CoLA
- Aggregate score: GLUE
Headline results
- MultiNLI matched / mismatched: 82.1 / 81.4 accuracy
- SNLI / SciTail / QNLI / RTE: 89.9 / 88.3 / 88.1 / 56.0 accuracy
- Story Cloze: 86.5 accuracy
- RACE-m / RACE-h / RACE: 62.9 / 57.4 / 59.0 accuracy
- CoLA / SST-2 / MRPC / STS-B / QQP / GLUE: 45.4 / 91.3 / 82.3 / 82.0 / 70.3 / 72.8
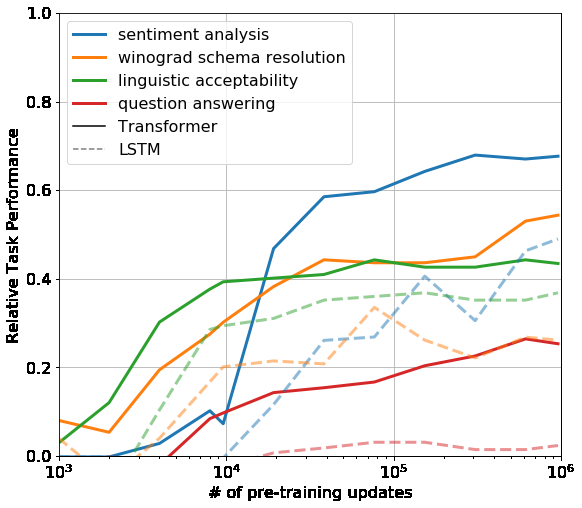
Ablations
- Remove pre-training: average score drops from 74.7 to 59.9.
- Replace Transformer with LSTM: average score drops from 74.7 to 69.1.
- Remove auxiliary LM objective: helps NLI and QQP, but slightly lowers average score pattern by task.
- Transfer more layers: gains rise monotonically, up to 9 points on MultiNLI.
Method Strengths and Weaknesses
Strengths
- One decoder-only backbone covers NLI, QA, similarity, and classification.
- Pre-training is decisive: removing it costs 14.8 average-score points.
- Transformer beats LSTM by 5.6 average points under the same transfer setup.
- Largest gains appear on long-context tasks: Story Cloze and RACE.
Weaknesses
- Pre-training uses only BooksCorpus, limiting data diversity.
- RTE stays below prior best: 56.0 versus 61.7.
- SST-2 is competitive, not state of the art.
- Zero-shot evaluation needs hand-built task heuristics.
Suggestions from the authors
- Test multi-task training on small supervised datasets such as RTE.
- Study stronger transfer mechanisms than traversal-style serialization.
- Characterize which linguistic functionality emerges during generative pre-training.
- Extend the method to broader unlabeled corpora and more tasks.
Links
Prior Papers
- @penningtonGloVe2014 — static embeddings are the earlier transfer baseline this paper surpasses.
- @petersELMo2018 — contextual LM pre-training is the closest transfer antecedent.
- @vaswaniAttentionAllNeed2017 — provides the Transformer backbone used for generative pre-training.
Further Papers
- @radfordGPT2_2019 — scales the same decoder-only pre-training recipe to much larger models and data.
- @brownGPT3_2020 — extends autoregressive pre-training into large-scale in-context learning.
- @devlinBERT2018 — pursues the same pre-train/fine-tune paradigm with a bidirectional objective.
- @raffelT5_2020 — generalizes transfer learning with large-scale text-to-text pre-training.