BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Problem
Framing
NLP pre-training still relied on left-to-right or shallow bidirectional objectives, so each token could not condition on full context during transfer. BERT closes this gap with masked bidirectional Transformer pre-training plus next-sentence prediction, then fine-tunes one encoder across tasks and sets new best results on 11 benchmarks.
Currently Used Methods
Foundational
- @bengioRepresentationLearning2013 — transferable representations from unlabeled data.
- Limitation in context: no deep bidirectional pre-training objective.
- @choGRU2014 — gated recurrent encoders for sequence modeling.
- Limitation in context: weaker parallelism and scaling than self-attention.
- @petersELMo2018 — contextual bi-LM features for downstream NLP.
- Limitation in context: feature extraction, not full-parameter fine-tuning.
- @radfordGPT2018 — Transformer pre-training with left-to-right LM.
- Limitation in context: unidirectional masking blocks full token conditioning.
- @vaswaniAttentionAllNeed2017 — Transformer encoder backbone with self-attention.
- Limitation in context: no masked bidirectional pre-training recipe.
Proposed Method
Architecture
BERT is a bidirectional Transformer encoder with token, segment, and position embeddings summed at input. It reports BERT with , , , 110M parameters, and BERT with , , , 340M.
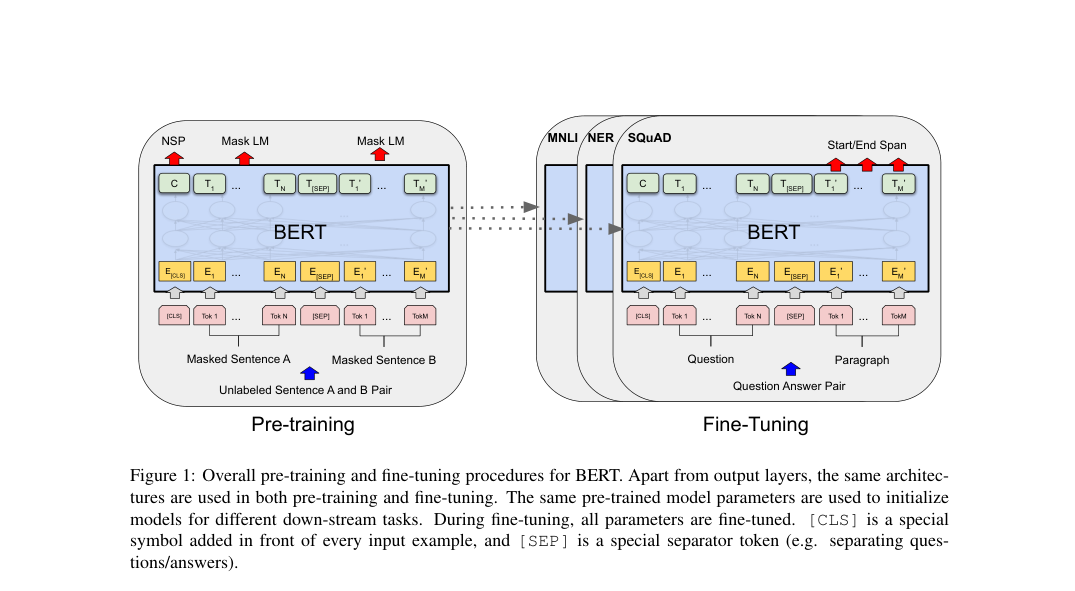
Loss / Objective
Pre-training sums masked LM and next-sentence prediction losses.
Algorithm
Task heads read either the state or token states from the shared encoder.
Training Procedure
- Pre-training corpora: BooksCorpus 800M words; English Wikipedia 2,500M words.
- Vocabulary: 30,000 WordPiece tokens.
- MLM prediction rate: 15% of tokens.
- MLM replacement: 80% , 10% random, 10% unchanged.
- NSP sampling: 50% IsNext, 50% NotNext.
- Optimizer: Adam.
- Learning rate: .
- Adam coefficients: , .
- Weight decay: 0.01.
- Warmup: 10,000 steps.
- Fine-tuning on GLUE: batch size 32, 3 epochs, learning rate in .
Evaluation
Datasets
- GLUE: MNLI, QQP, QNLI, SST-2, CoLA, STS-B, MRPC, RTE.
- SQuAD v1.1.
- SQuAD v2.0.
- SWAG.
Metrics
- Accuracy for most GLUE tasks and SWAG.
- F1 for QQP and MRPC.
- Spearman correlation for STS-B.
- EM and F1 for SQuAD.
Headline results
- GLUE test, BERT: average 82.1.
- MNLI test, BERT: 86.7 matched, 85.9 mismatched.
- QNLI test, BERT: 92.7.
- SQuAD v1.1 test, BERT + TriviaQA: 85.1 EM, 91.8 F1.
- SWAG test, BERT: 86.3.
Table 1: GLUE test results across eight tasks.
| System | MNLI-(m/mm) | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | Average |
|---|---|---|---|---|---|---|---|---|---|
| Pre-OpenAI SOTA | 80.6/80.1 | 66.1 | 82.3 | 93.2 | 35.0 | 81.0 | 86.0 | 61.7 | 74.0 |
| BiLSTM+ELMo+Attn | 76.4/76.1 | 64.8 | 79.8 | 90.4 | 36.0 | 73.3 | 84.9 | 56.8 | 71.0 |
| OpenAI GPT | 82.1/81.4 | 70.3 | 87.4 | 91.3 | 45.4 | 80.0 | 82.3 | 56.0 | 75.1 |
| BERTBASE | 84.6/83.4 | 71.2 | 90.5 | 93.5 | 52.1 | 85.8 | 88.9 | 66.4 | 79.6 |
| BERTLARGE | 86.7/85.9 | 72.1 | 92.7 | 94.9 | 60.5 | 86.5 | 89.3 | 70.1 | 82.1 |
Ablations
- Remove NSP: MNLI drops 84.4 to 83.9; SQuAD drops 88.5 to 87.9.
- Replace bidirectional MLM with left-to-right LM: SQuAD falls to 77.8 F1.
- Larger models help most on low-resource tasks such as RTE.
- More pre-training steps improve downstream accuracy.
Method Strengths and Weaknesses
Strengths
- One encoder transfers across classification, tagging, and extractive QA.
- Bidirectional MLM beats left-to-right pre-training in ablations.
- BERT reaches 82.1 average on GLUE test.
- Fine-tuning adds only small task-specific heads.
Weaknesses
- creates a pre-train and fine-tune mismatch.
- NSP is a coarse binary discourse signal.
- Gains depend on large corpora and heavy pre-training compute.
- BERT fine-tuning is unstable on small datasets.
Suggestions from the authors
- Scale depth, hidden size, and attention heads further.
- Study masking schemes that reduce the mismatch.
- Pre-train on larger corpora and additional languages.
- Extend the same recipe to more downstream task families.
Links
Prior Papers
- @bengioRepresentationLearning2013 — frames the transfer-from-unlabeled-data motivation that BERT operationalizes.
- @choGRU2014 — represents the recurrent encoder line that bidirectional Transformers supplant.
- @petersELMo2018 — the closest contextual pre-training baseline, but feature-based rather than end-to-end fine-tuned.
- @radfordGPT2018 — the direct autoregressive Transformer pre-training baseline that BERT outperforms on GLUE.
- @vaswaniAttentionAllNeed2017 — supplies the Transformer encoder backbone that BERT turns into a bidirectional language model.
Further Papers
- @radfordGPT2_2019 — extends large-scale Transformer pre-training with a purely autoregressive objective after BERT.
- @brownGPT3_2020 — scales language-model pre-training dramatically and shifts transfer toward prompting.
- @raffelT5_2020 — reformulates transfer learning as text-to-text pre-training and fine-tuning.
- @huLoRA2021 — targets parameter-efficient adaptation of large pre-trained Transformers.
- @radfordCLIP2021 — extends pre-training and transfer to multimodal supervision with Transformer backbones.