Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Problem
Framing
Phrase-based SMT used count-derived phrase scores and shallow neural features, but lacked a learned conditional model for variable-length phrase pairs. This paper closes that gap with an encoder–decoder RNN that maps source phrases to target phrases through a fixed context vector and improves Moses test BLEU from 33.30 to 33.87.
Currently Used Methods
Foundational
- @hochreiterLSTM1997 — gated recurrent memory for long-range sequence modeling.
- Limitation in context: not an encoder–decoder phrase translation feature.
- @mikolovWord2vec2013 — distributed word embeddings from predictive objectives.
- Limitation in context: learns token semantics, not conditional phrase mappings.
- @sutskeverSeq2Seq2014 — encoder–decoder RNN for sequence transduction.
- Limitation in context: not used as a phrase-table score inside SMT.
- "Statistical Phrase-Based Translation" — log-linear SMT with phrase-table and language-model features.
- Limitation in context: phrase scores come from sparse counts, not learned composition.
- "Learning Semantic Representations for the Phrase Translation Model" — neural phrase scoring for SMT.
- Limitation in context: lacks recurrent generation and gated sequence compression.
Proposed Method
Architecture
An encoder RNN reads into a fixed vector . A decoder RNN predicts target tokens autoregressively from previous outputs and . The recurrent unit adds reset and update gates to control overwrite.
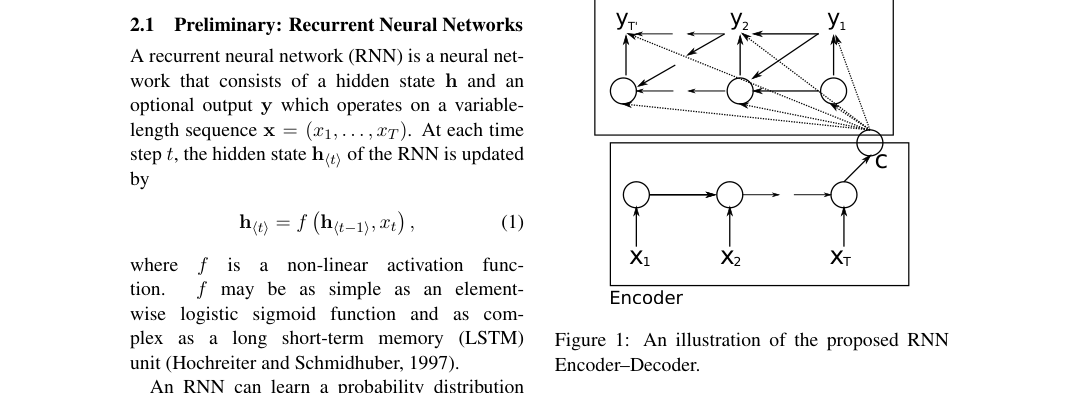
Loss / Objective
The model maximizes conditional log-likelihood over phrase pairs.
Sampling Rule / Algorithm
The decoder factorizes the target phrase left-to-right.
Gated Hidden Unit
The new recurrent unit interpolates between copying the old state and writing a candidate state.
Training Procedure
- Training pairs: 15M English–French phrase pairs.
- Phrase length cap: 7 words per side.
- Vocabulary: 15k most frequent words per language.
- Embedding size: 620.
- Hidden size: 1000.
- Optimizer: Adadelta.
- Minibatch size: 64.
- Gradient clipping: norm threshold 1.
Evaluation
Datasets
- WMT'14 English–French SMT setup.
- Phrase-table subset: 15M phrase pairs.
- Source and target phrases capped at 7 words.
Metrics
- BLEU on development and test sets.
- Phrase-pair ranking quality.
- Qualitative phrase generation samples.
- Word and phrase embedding geometry.
Headline results
- English–French baseline: BLEU 30.64 dev, 33.30 test.
- Baseline + RNN: BLEU 31.20 dev, 33.87 test.
- Baseline + CSLM: BLEU 31.48 dev, 34.64 test.
- Baseline + CSLM + RNN: BLEU 31.50 dev, 34.54 test.
Qualitative analysis
The model prefers linguistically regular targets over raw phrase-table frequency and can sample plausible continuations.
Table 4: Samples from RNN Encoder–Decoder for selected source phrases
| Source | Samples from RNN Encoder–Decoder |
|---|---|
| at the end of the | [à la fin de la] (\times11) |
| for the first time | [pour la première fois] (\times24) [pour la première fois que] (\times2) |
| in the United States and | [aux États-Unis et] (\times6) [dans les États-Unis et] (\times4) |
| , as well as | [, ainsi que] [,] [ainsi que] [, ainsi qu’] [et UNK] |
| one of the most | [l’ un des plus] (\times9) [l’ un des] (\times5) [l’ une des plus] (\times2) |
Ablations
- Add RNN phrase scores: improves BLEU over the baseline.
- Add CSLM alone: gives the largest test gain.
- Add CSLM with RNN: improves dev BLEU, not test BLEU.
- Remove frequency bias in training: favors regular phrase mappings.
Method Strengths and Weaknesses
Strengths
- Introduces the encoder–decoder template for variable-length conditional generation.
- GRU gating is simpler than LSTM and directly controls overwrite.
- Adds one SMT feature that lifts test BLEU from 33.30 to 33.87.
- Learns structured phrase representations and plausible phrase samples.
Weaknesses
- Fixed context vector creates a compression bottleneck.
- RNN feature trails CSLM alone on test BLEU.
- Evaluation stays within one English–French SMT pipeline.
- Training restricts phrases to length at most 7.
Suggestions from the authors
- Apply the encoder–decoder beyond phrase scoring to broader sequence transduction.
- Study the geometry of learned word and phrase embeddings.
- Extend training from short phrases to longer sequences.
- Combine the model more effectively with other neural SMT components.
Links
Prior Papers
- @hochreiterLSTM1997 — establishes gated recurrent memory, which this paper simplifies into reset and update gates.
- @mikolovWord2vec2013 — provides distributed embeddings, extended here from words to conditional phrase representations.
- @sutskeverSeq2Seq2014 — shares the encoder–decoder formulation for sequence transduction.
Further Papers
- @bahdanauAttention2014 — removes the fixed-context bottleneck by attending over encoder states.
- @vaswaniAttentionAllNeed2017 — keeps sequence transduction but replaces recurrence with self-attention.
- @petersELMo2018 — continues contextual recurrent representation learning for language.
- @devlinBERT2018 — pushes sequence representation learning toward large-scale contextual pretraining.