Efficient Estimation of Word Representations in Vector Space
Efficient Estimation of Word Representations in Vector Space
Problem
Framing
Neural word embeddings had not scaled past a few hundred million tokens without expensive hidden-layer language models. The paper closes this gap with two shallow log-linear architectures, CBOW and skip-gram, that learn high-quality vectors on billion-token corpora in about a day.
Currently Used Methods
Foundational
- @bengioRepresentationLearning2013 — feedforward NNLM with learned projection and nonlinear hidden layer.
- Limitation in context: hidden-layer cost blocks billion-token, million-word training.
- A Recurrent Neural Network Based Language Model — recurrent LM with hidden-state memory.
- Limitation in context: recurrence stays expensive for large-vocabulary embedding learning.
- A Fast and Simple Neural Probabilistic Language Model — two-stage neural word-vector pretraining.
- Limitation in context: still trails the paper's simpler large-scale log-linear training.
- Latent Semantic Analysis — global matrix-factorized word representations.
- Limitation in context: weaker linear regularities on analogy structure.
- Latent Dirichlet Allocation — topic-mixture word representations.
- Limitation in context: computationally expensive on very large corpora.
Proposed Method
Architecture
The paper proposes two shallow shared-embedding models with no nonlinear hidden layer. CBOW averages context vectors from four past and four future words to predict the center word. Skip-gram uses the center word to predict surrounding words within a sampled window up to .
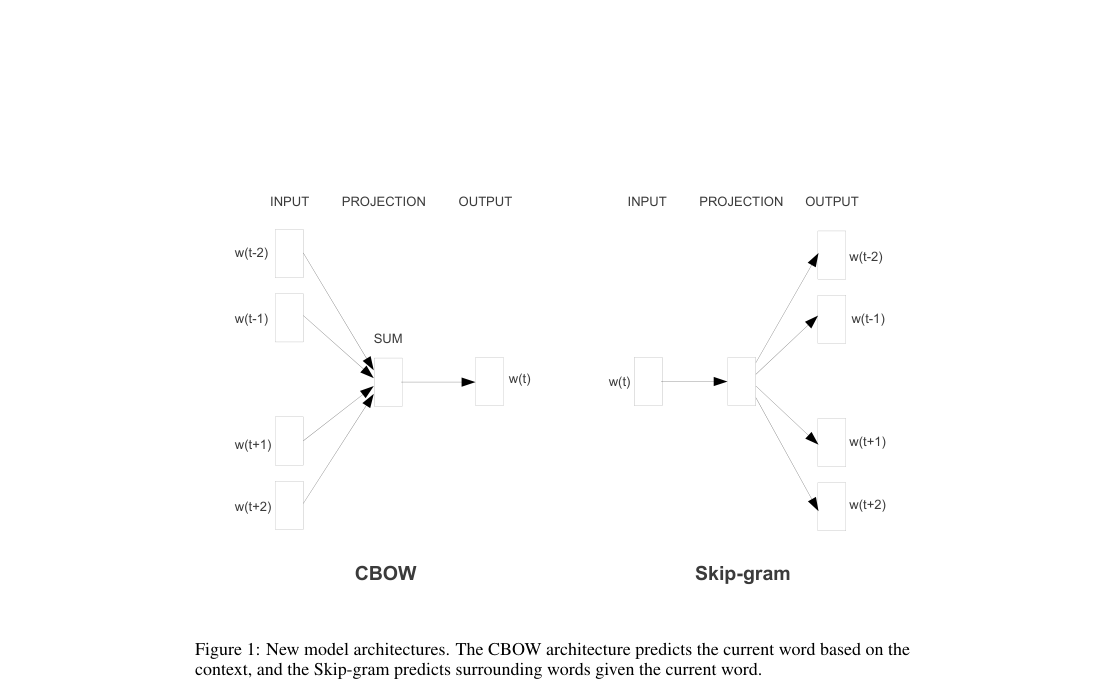
Loss / Objective
The paper minimizes per-token training complexity under hierarchical softmax.
Algorithm
Word relations are tested by vector offsets and nearest-neighbor retrieval.
Training Procedure
- Optimizer: stochastic gradient descent with backpropagation.
- Output layer: hierarchical softmax with a Huffman tree.
- CBOW context: 4 history + 4 future words.
- Skip-gram window: sample .
- Maximum skip-gram distance: .
- Main single-machine runs: 3 epochs, then 1 epoch on larger data.
- Learning rate: 0.025 linearly decayed to 0.
- Distributed setup: asynchronous mini-batch Adagrad.
- DistBelief replicas: 50–100.
Evaluation
Datasets
- Google News corpus: about 6B tokens, 1M-word vocabulary.
- Smaller subsets: 24M to 783M training words.
- Semantic–Syntactic Word Relationship test set.
- MSR syntactic relationship set.
- Microsoft Research Sentence Completion Challenge.
Metrics
- Semantic analogy accuracy (%).
- Syntactic analogy accuracy (%).
- Total analogy accuracy (%).
- MSR accuracy (%).
- Sentence completion accuracy (%).
- Training time (days or days CPU cores).
Headline results
- CBOW, 783M words, 300d: 45.9% restricted analogy accuracy.
- CBOW, 783M words, 600d: 50.4% restricted analogy accuracy.
- 640d CBOW: 24% semantic, 64% syntactic, 57% total, 36% MSR.
- 640d skip-gram: 55% semantic, 59% syntactic, 58% total, 44% MSR.
- Sentence completion: skip-gram 48%; skip-gram + RNNLM 58.9%.
Table 1: Restricted analogy accuracy for CBOW across vector dimensionality and training words.
| Dimensionality / Training words | 24M | 49M | 98M | 196M | 391M | 783M |
|---|---|---|---|---|---|---|
| 50 | 13.4 | 15.7 | 18.6 | 19.1 | 22.5 | 23.2 |
| 100 | 19.4 | 23.1 | 27.8 | 28.7 | 33.4 | 32.2 |
| 300 | 23.2 | 29.2 | 35.3 | 38.6 | 43.7 | 45.9 |
| 600 | 24.0 | 30.1 | 36.5 | 40.8 | 46.6 | 50.4 |
Ablations
- Training words vs dimensionality: more data helps as much as larger vectors.
- CBOW vs skip-gram: CBOW favors syntax; skip-gram favors semantics.
- Epoch count: one epoch on more data beats three on less data.
- Distributed training: enables 6B-token runs with 300d–1000d vectors.
Method Strengths and Weaknesses
Strengths
- Removes the hidden layer and states training complexity in closed form.
- Learns strong semantic structure from simple vector arithmetic.
- Trains 300d billion-token vectors in about one day.
- Separates CBOW and skip-gram trade-offs cleanly.
Weaknesses
- Emphasizes complexity formulas more than a full probabilistic objective.
- Skip-gram is slower than CBOW on large runs.
- Sentence completion trails strong recurrent language models alone.
- Evaluation centers on analogy accuracy, not downstream tasks.
Suggestions from the authors
- Train on larger corpora with higher-dimensional vectors.
- Use multiple examples to estimate relation directions.
- Apply embeddings to translation, retrieval, and question answering.
- Explore tasks that exploit linear semantic structure.
Links
Prior Papers
- @bengioRepresentationLearning2013 — establishes neural language modeling with learned embeddings, which this paper simplifies aggressively.
Further Papers
- @choGRU2014 — extends continuous word representations into encoder–decoder sequence modeling.
- @penningtonGloVe2014 — offers a count-based alternative to local-context word2vec training.
- @petersELMo2018 — replaces static word vectors with contextual token representations.