Deep Contextualized Word Representations
Deep Contextualized Word Representations
Problem
Framing
Static embeddings assign one vector per type and miss polysemy and context-sensitive syntax. ELMo closes this with a deep bidirectional LM whose internal layers are mixed per task into token-specific features. Across six benchmarks, it reports 6–20% relative error reductions.
Currently Used Methods
Foundational
- @mikolovWord2vec2013 — static distributional word vectors from unlabeled text.
- Limitation in context: one vector per type cannot model contextual meaning.
- @penningtonGloVe2014 — global-count embeddings with strong transfer performance.
- Limitation in context: context independence misses polysemy and sentence-specific use.
- @hochreiterLSTM1997 — recurrent sequence modeling for context-sensitive token states.
- Limitation in context: task-specific training does not yield universal pretrained token features.
- Learned in Translation: Contextualized Word Vectors — MT-encoder contextual word representations.
- Limitation in context: parallel-data dependence limits scale and domain coverage.
- context2vec: Learning Generic Context Embedding with Bidirectional LSTM — bidirectional LSTM context encoding around a pivot.
- Limitation in context: weaker downstream integration than deep task-weighted biLM mixing.
Proposed Method
Architecture
ELMo uses a 2-layer biLM with separate forward and backward LSTMs. Each direction has 4096 hidden units with 512-dimensional projections; the token layer is a character CNN with 2048 filters, two highway layers, and a 512-dimensional projection. The second LSTM layer receives a residual connection.
Loss / Objective
The biLM maximizes coupled forward and backward LM likelihoods, then forms a task-specific scalar mix of all layers.
Algorithm
The downstream model freezes the biLM, runs it once, and concatenates the mixed representation at the input or output.
Training Procedure
- Pretrain on the 1B Word Benchmark.
- Train for 10 epochs.
- Use biLSTM layers.
- Each LSTM: 4096 hidden units, 512-dimensional projection.
- Character CNN: 2048 filters.
- Two highway layers.
- Residual connection from layer 1 to layer 2.
- Add dropout to ELMo in downstream models.
- Optionally regularize mix weights with .
Evaluation
Datasets
- SQuAD
- SNLI
- Semantic role labeling
- Coreference resolution
- Named entity recognition
- Constituency parsing
- Word sense disambiguation
- POS tagging
Metrics
- F1
- Accuracy
- Relative error reduction
- Perplexity
Headline results
- SQuAD test: F1 81.1 85.8; ensemble F1 87.4.
- SNLI: accuracy 88.1 89.5.
- SRL: F1 81.6 84.6.
- Six-task summary: 6–20% relative error reduction over strong baselines.
- biLM pretraining: average forward/backward perplexity 39.7.
Ablations
- Layer mixing: all-layer scalar mixing beats last-layer-only features on SQuAD, SNLI, and SRL.
- Placement: SQuAD and SNLI gain from input plus output injection; SRL peaks with input injection.
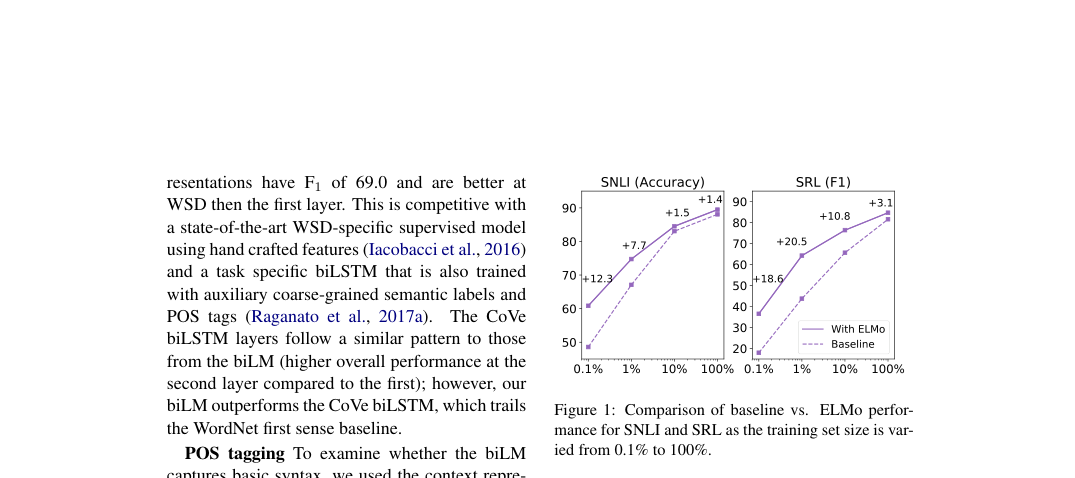
- Data scale: ELMo improves sample efficiency most in low-resource training.
- Layer roles: lower biLM layers encode syntax; upper layers encode semantics.
Method Strengths and Weaknesses
Strengths
- Drops into existing task architectures with only concatenation and scalar-mix parameters.
- All-layer mixing beats top-layer-only contextual features.
- Improves six diverse benchmarks with new state-of-the-art results.
- Strong low-resource gains increase sample efficiency.
Weaknesses
- Running a large 2-layer biLM adds substantial inference cost.
- biLM perplexity 39.7 trails stronger forward-only LM baselines.
- Downstream quality depends on hand-chosen insertion points.
- Features are frozen; task supervision cannot fully adapt the encoder.
Suggestions from the authors
- Apply ELMo to more NLP tasks beyond the six benchmarks.
- Fine-tune the biLM on domain text for domain transfer.
- Analyze which linguistic signals each biLM layer captures.
- Explore richer ways to inject contextual features into task models.
Links
Prior Papers
- @mikolovWord2vec2013 — Static word vectors are the main context-independent baseline ELMo replaces.
- @penningtonGloVe2014 — GloVe is the canonical pretrained embedding baseline that ELMo augments.
- @hochreiterLSTM1997 — ELMo’s biLM is built from LSTM sequence encoders.
- @choGRU2014 — The SQuAD baseline uses GRUs, showing ELMo plugs into non-LSTM sequence models.
Further Papers
- @devlinBERT2018 — Extends contextual pretraining from frozen biLM features to deeply bidirectional Transformer encoders.
- @radfordGPT2018 — Studies transfer from pretrained language-model representations in the same year.
- @radfordGPT2_2019 — Scales pretrained contextual language modeling into stronger generative transfer.
- @brownGPT3_2020 — Pushes large-scale pretrained language-model transfer to a new scale regime.