Language Models are Unsupervised Multitask Learners
Language Models are Unsupervised Multitask Learners
Problem
Framing
Supervised transfer in NLP still bound each task to labeled adaptation. The paper argues that scaling one decoder-only language model on WebText yields zero-shot task behavior from prompting alone. The largest model has 1.5B parameters and improves on CoQA, WMT-14 Fr→En, CNN/Daily Mail, and Natural Questions.
Currently Used Methods
Foundational
- @radfordGPT2018 — generative pretraining with supervised downstream fine-tuning.
- Limitation in context: each task still needs labeled adaptation.
- @vaswaniAttentionAllNeed2017 — Transformer decoder for scalable autoregressive sequence modeling.
- Limitation in context: architecture alone does not yield zero-shot transfer.
- @petersELMo2018 — contextual representations transferred into supervised task models.
- Limitation in context: requires separate task heads and labeled training.
- @devlinBERT2018 — strong bidirectional pretraining with fine-tuned task performance.
- Limitation in context: evaluation still centers on supervised adaptation.
Proposed Method
Architecture
GPT-2 is a decoder-only Transformer with byte-level BPE inputs and context length 1024. Model sizes scale from 117M, 12 layers, to 1542M, 48 layers, . Tasks are specified only by the prompt prefix.
Loss / Objective
Training uses standard autoregressive maximum likelihood.
Sampling Rule / Algorithm
Zero-shot inference conditions on a task prompt and samples the same next-token distribution.
Training Procedure
- Data: WebText, about 8 million documents, about 40 GB.
- Source filter: outbound Reddit links with at least 3 karma.
- Context length: 1024 tokens.
- Model sizes: 117M, 345M, 762M, 1542M.
- Qualitative decoding: top- sampling with .
Evaluation
Datasets
- CoQA
- WMT-14 Fr→En
- CNN/Daily Mail
- Natural Questions
- LAMBADA
- CBT
- WikiText-2
- PTB
- enwik8
- text8
- WikiText-103
- 1BW
Metrics
- F1
- BLEU
- ROUGE-1
- ROUGE-2
- ROUGE-L
- ROUGE-AVG
- Accuracy
- Perplexity
- Bits per byte
- Bits per character
Headline results
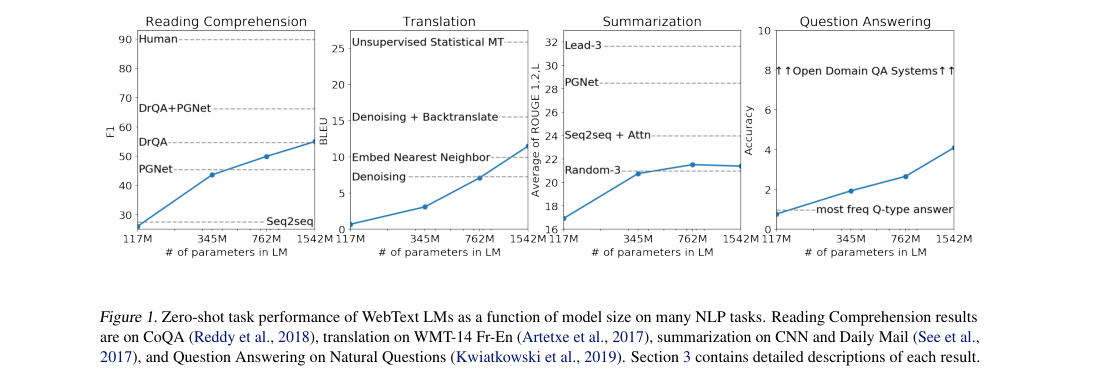
- CoQA zero-shot: 55.0 F1.
- WMT-14 Fr→En zero-shot: 11.5 BLEU.
- CNN/Daily Mail zero-shot with TL;DR hint: ROUGE-AVG 21.40.
- Natural Questions zero-shot: about 4.1 accuracy.
- LAMBADA zero-shot: 8.63 perplexity, 63.24% accuracy.
Table 1: CNN/Daily Mail summarization ROUGE F1 results
| Model | R-1 | R-2 | R-L | R-AVG |
|---|---|---|---|---|
| Bottom-Up Sum | 41.22 | 18.68 | 38.34 | 32.75 |
| Lede-3 | 40.38 | 17.66 | 36.62 | 31.55 |
| Seq2Seq + Attn | 31.33 | 11.81 | 28.83 | 23.99 |
| GPT-2 TL;DR: | 29.34 | 8.27 | 26.58 | 21.40 |
| Random-3 | 28.78 | 8.63 | 25.52 | 20.98 |
| GPT-2 no hint | 21.58 | 4.03 | 19.47 | 15.03 |
Ablations
- Model size: zero-shot performance improves monotonically across tasks.
- Prompt hinting:
TL;DR:sharply improves summarization over no hint. - Data overlap: CoQA news overlap reaches about 15% and explains only part of gains.
- Task format: natural language prefixes can elicit translation and QA without fine-tuning.
Method Strengths and Weaknesses
Strengths
- Unifies many tasks under one next-token objective.
- Zero-shot gains rise smoothly with scale across four task families.
- No task-specific parameters or gradient updates at evaluation.
- Prompted summarization beats random and no-hint baselines.
Weaknesses
- Zero-shot results still trail supervised systems on core benchmarks.
- Prompt phrasing strongly affects performance.
- Benchmark contamination is nontrivial on CoQA news.
- Context stays limited to 1024 tokens.
Suggestions from the authors
- Train on larger and more diverse corpora.
- Measure contamination more rigorously across benchmarks.
- Test broader task families under pure zero-shot prompting.
- Study how context specifies latent tasks.
Links
Prior Papers
- @radfordGPT2018 — direct predecessor that uses generative pretraining before GPT-2 drops task-specific fine-tuning.
- @vaswaniAttentionAllNeed2017 — provides the Transformer decoder backbone that GPT-2 scales.
- @petersELMo2018 — earlier pretraining transfer method that still relies on supervised downstream models.
- @devlinBERT2018 — strong contemporaneous pretraining baseline centered on fine-tuned adaptation.
Further Papers
- @brownGPT3_2020 — extends the same scaling thesis to in-context few-shot learning.
- @kaplanScalingLaws2020 — formalizes scaling behavior that GPT-2 demonstrates empirically.
- @ouyangInstructGPT2022 — adapts GPT-style pretrained models toward instruction following.
- @hoffmannChinchilla2022 — revisits compute-optimal scaling for large autoregressive language models.