Training Language Models to Follow Instructions with Human Feedback
Training Language Models to Follow Instructions with Human Feedback
Problem
Framing
Scaling GPT-3 does not make it follow instructions, tell the truth, or avoid toxic output. The paper closes this gap with a three-stage RLHF pipeline: supervised demonstrations, a learned reward model, and PPO fine-tuning. A 1.3B InstructGPT model is preferred to 175B GPT-3 outputs in human evaluation.
Currently Used Methods
Foundational
- @brownGPT3_2020 — large autoregressive language models steered by prompting.
- Limitation in context: next-token training does not optimize instruction following.
- @christianoRLHF2017 — preference learning from pairwise human comparisons.
- Limitation in context: not instantiated for open-ended language generation at GPT scale.
- @schulmanPPO2017 — clipped policy optimization for stable RL updates.
- Limitation in context: needs a learned reward aligned to text outputs.
- @radfordGPT2_2019 — pretrained generative transformers transferred by prompting and fine-tuning.
- Limitation in context: no mechanism for preference-level alignment.
- Learning to Summarize from Human Feedback — RLHF on a narrower summarization domain.
- Limitation in context: does not cover broad API-style instruction prompts.
Proposed Method
Architecture
The policy uses GPT-3 backbones at 1.3B, 6B, and 175B parameters. The reward model shares the transformer body but replaces the unembedding head with a scalar score; PPO adds a value head and regularizes to the SFT policy.
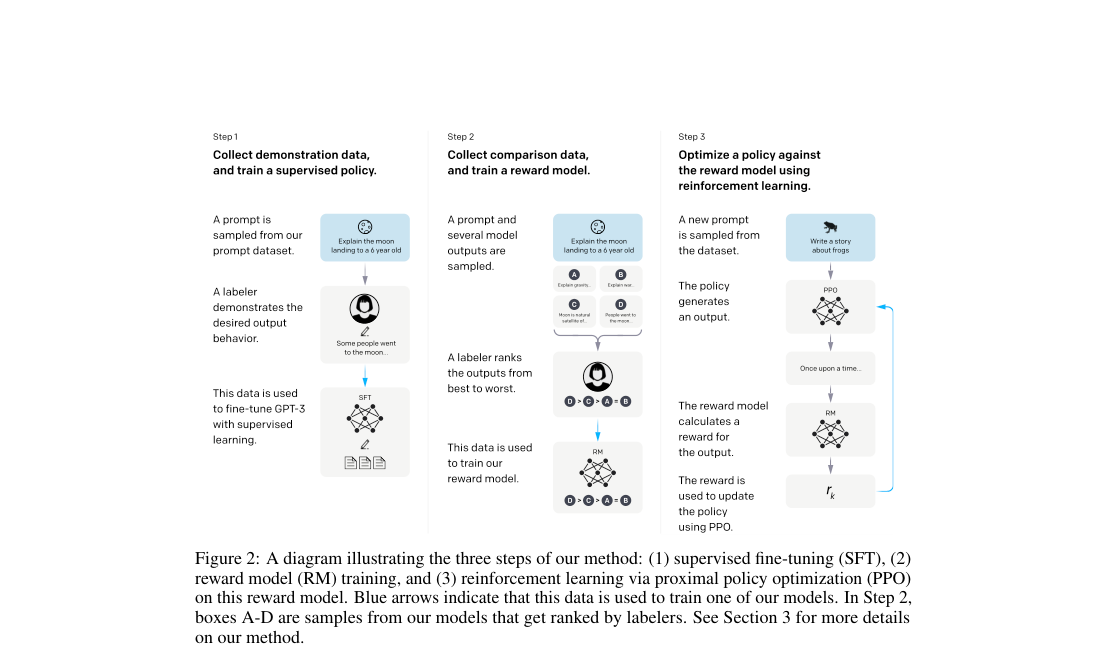
Loss / Objective
Reward learning fits pairwise preferences; policy learning maximizes reward with KL control and an optional pretraining mix.
Algorithm
PPO treats each prompt-response pair as a bandit episode and uses the reward model plus KL penalty as the scalar return.
Training Procedure
- SFT epochs: 16.
- SFT dropout: 0.2.
- SFT learning rate: for 1.3B/6B; for 175B.
- SFT batch size: 32 for 1.3B/6B; 8 for 175B.
- LR schedule: cosine decay to 10%, no warmup.
- PPO init model: 2 SFT epochs with 10% pretraining mix.
- Reward model size: 6B.
- PPO KL coefficient: .
- PPO training length: 256k episodes.
- PPO prompt pool: about 31k prompts.
Evaluation
Datasets
- OpenAI API prompts with held-out customer splits.
- Labeler-written prompts.
- TruthfulQA.
- RealToxicityPrompts.
- Public NLP tasks: SQuAD, DROP, HellaSwag, WMT 2015 FrEn.
Metrics
- Human preference win rate.
- Helpfulness ratings.
- Truthfulness and informativeness judgments.
- Toxicity scores and human toxicity labels.
- Zero-shot or few-shot task accuracy.
Headline results
- API prompts, 1.3B: InstructGPT outputs are preferred to 175B GPT-3.
- API prompts, all scales: PPO-ptx beats GPT, prompted GPT, and SFT baselines.
- TruthfulQA: PPO improves truthful and informative answers over GPT-3.
- RealToxicityPrompts: about 25% fewer toxic outputs when prompted respectfully.
- Public NLP tasks: plain PPO regresses; PPO-ptx recovers much of the loss.
Table 1: Held-out-worker preference results on the instruct distribution, cropped as a line plot rather than a readable numeric table.
| Observation | Value |
|---|---|
| Compared systems | GPT, prompted GPT, SFT, PPO, PPO-ptx |
| X-axis | Model size: 1.3B, 6B, 175B |
| Y-axis | Win rate against SFT 175B |
| Main pattern | PPO-ptx is highest across scales |
| Secondary pattern | PPO also beats SFT and GPT baselines |
Ablations
- Pretraining-mix coefficient : larger values recover public-task performance.
- KL coefficient : both too small and too large degrade preference results.
- PPO training length: longer runs worsen public benchmark regression.
- PPO vs PPO-ptx: pretraining mix reduces the alignment tax.
Method Strengths and Weaknesses
Strengths
- Shows 1.3B aligned outputs beat 175B GPT-3 in human preference.
- Cleanly separates demonstration learning, reward fitting, and policy optimization.
- KL regularization anchors RL updates to a competent reference policy.
- Pretraining mix directly targets public-benchmark regressions.
Weaknesses
- Optimizes for labeler preferences, not a broader value model.
- Plain PPO hurts SQuAD, DROP, HellaSwag, and translation performance.
- Reward-model errors can be amplified by policy optimization.
- The pipeline is expensive: SFT, reward training, then 256k PPO episodes.
Suggestions from the authors
- Reduce public-task regressions during RLHF optimization.
- Study reward-model generalization across prompts and labelers.
- Improve robustness on truthfulness, toxicity, and bias failures.
- Clarify how preference alignment relates to broader human values.
Links
Prior Papers
- @brownGPT3_2020 — provides the pretrained GPT-3 base model that InstructGPT aligns.
- @christianoRLHF2017 — supplies the preference-learning template for reward-model training.
- @schulmanPPO2017 — supplies the PPO optimizer used for policy fine-tuning.
- @radfordGPT2_2019 — establishes the autoregressive transformer LM lineage that InstructGPT extends.
Further Papers
- @kojimaZeroShotCoT2022 — tests instruction-following reasoning behavior in aligned large language models.