Deep Reinforcement Learning from Human Preferences
Deep Reinforcement Learning from Human Preferences
Problem
Framing
Deep RL assumed access to a numeric reward, but many goals are easier to judge than specify. The paper closes this gap by fitting a reward model from pairwise human clip comparisons and optimizing that model online. Human feedback covers under 1% of agent interactions.
Currently Used Methods
Foundational
- @mnihDQN2015 — deep Q-learning succeeds on Atari with explicit game rewards.
- Limitation in context: cannot act when the reward is unobserved.
- @schulmanPPO2017 — practical policy-gradient optimization for large continuous-control problems.
- Limitation in context: still requires a scalar objective to optimize.
- @silverAlphaGo2016 — superhuman RL under exact win-loss objectives.
- Limitation in context: depends on perfectly specified task outcomes.
- Apprenticeship Learning via Inverse Reinforcement Learning — infers rewards from expert demonstrations.
- Limitation in context: demonstrations fail for hard or non-human behaviors.
- Active Preference-Based Learning — learns utilities from pairwise preference queries.
- Limitation in context: did not scale to deep RL domains.
Proposed Method
Architecture
The system has three parts: policy, environment, and reward predictor. The policy generates trajectories, humans compare short clip pairs, and the reward predictor trains asynchronously from those labels. RL then maximizes predicted reward instead of environment reward.

Loss / Objective
The reward model uses a Bradley–Terry preference likelihood over clip returns.
Algorithm
Policy optimization is standard RL on the current learned reward.
Training Procedure
- Clip length: 1–2 seconds.
- Query choice: ensemble disagreement over segment pairs.
- Reward model: bootstrap ensemble.
- Predictor holdout fraction: .
- MuJoCo optimizer: TRPO.
- MuJoCo discount: .
- Atari reward-model pretraining: 200 epochs.
Evaluation
Datasets
- Atari: BeamRider, Breakout, Pong, Q*bert, Seaquest, SpaceInvaders, Enduro.
- MuJoCo: 8 continuous-control tasks.
- Novel tasks: Hopper backflip, one-leg Half-Cheetah, Enduro traffic pacing.
Metrics
- True environment return.
- Human query count.
- Environment interactions.
- Qualitative success on novel behaviors.
Headline results
- MuJoCo: 700 labels nearly match true-reward RL.
- MuJoCo: 1400 labels slightly outperform true-reward RL.
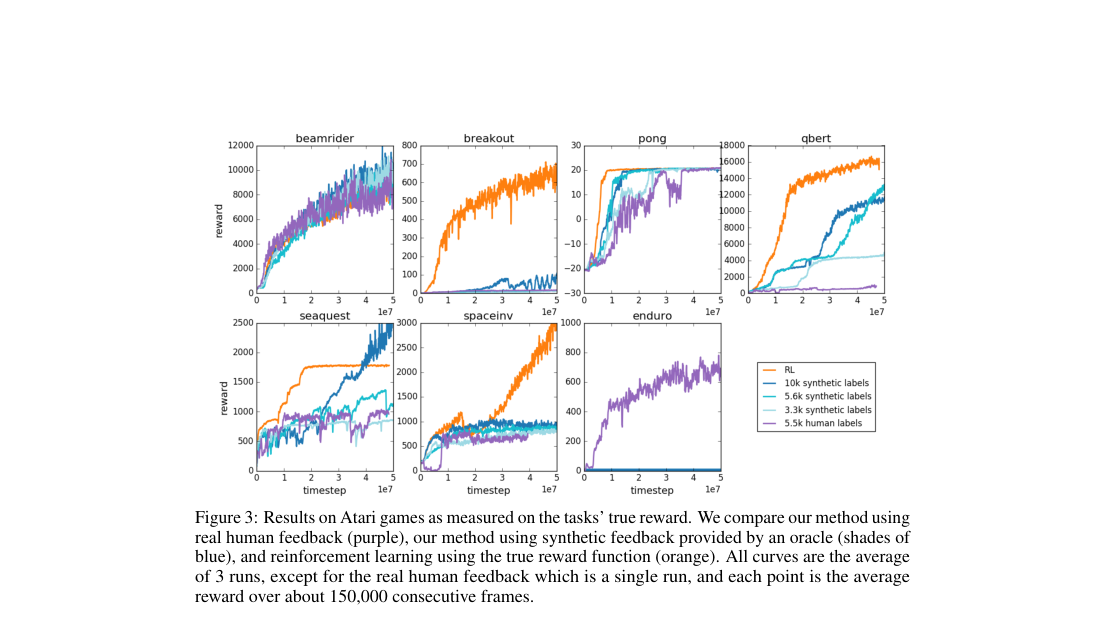
- Atari: 5.5k human queries learn competitive policies on most games.
- Oversight cost: feedback covers less than 1% of interactions.
- Hopper backflip: about 900 queries, under one hour.
Ablations
- Query strategy: random queries underperform disagreement-based selection.
- Reward ensemble: one predictor degrades learning quality.
- Label timing: offline reward training yields bizarre exploitative behavior.
- Episode design: variable termination leaks task information.
Method Strengths and Weaknesses
Strengths
- Learns reward functions from pairwise judgments, not hand-coded scores.
- Reaches strong Atari and MuJoCo performance with sparse oversight.
- Online querying reduces reward-model exploitation.
- Trains novel behaviors humans can judge but not demonstrate.
Weaknesses
- Learned-reward training is less stable than true-reward RL.
- Human-labeled Atari trails oracle-label runs on several games.
- Reward hacking appears when reward learning is offline.
- Performance remains weak on some games, especially Q*bert.
Suggestions from the authors
- Improve consistency and quality of human labels.
- Tighten online feedback loops against predictor exploitation.
- Extend preference learning to harder real-world tasks.
- Reduce the amount of feedback needed further.
Links
Prior Papers
- @mnihDQN2015 — establishes high-performing deep RL under explicit rewards, the assumption removed here.
- @schulmanPPO2017 — represents scalable policy optimization around learned reward objectives.
- @silverAlphaGo2016 — exemplifies success when the task objective is exactly specified.
- @silverAlphaZero2018 — extends exact-objective self-play RL, contrasting with preference-defined goals.
Further Papers
- @ouyangInstructGPT2022 — extends reward modeling from human preferences to language-model alignment.
- @schulmanPPO2017 — provides a practical optimizer widely reused in later preference-based RL setups.