A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and Go through Self-Play
A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and Go through Self-Play
Problem
Framing
Chess and shogi engines still depended on handcrafted evaluation and alpha-beta heuristics, while AlphaGo Zero remained tied to Go-friendly symmetries and binary outcomes. AlphaZero closes this with one tabula-rasa self-play algorithm that uses only game rules, a shared policy-value network, and MCTS. It reaches superhuman chess and shogi within 24 hours.
Currently Used Methods
Foundational
- @silverAlphaGo2016 — policy-value self-play with neural-guided tree search for Go.
- Limitation in context: exploits Go symmetries and binary outcomes, not chess or shogi.
- NeuroChess — neural chess evaluation from 175 handcrafted features with TD learning.
- Limitation in context: depends on engineered inputs and weak depth-2 search.
- KnightCap — TD(leaf) neural evaluation inside alpha-beta search.
- Limitation in context: still relies on domain-specific search and hand-initialised weights.
- Giraffe — self-play neural chess evaluation reaching master-level strength.
- Limitation in context: remains coupled to alpha-beta search and crafted representations.
- DeepChess — supervised pairwise position ranking from expert human games.
- Limitation in context: learns from human data, not tabula-rasa self-play.
Proposed Method
Architecture
AlphaZero learns one network over board-plane inputs and legal-move outputs. The state tensor is with history steps; chess uses 119 input planes and an policy head, shogi uses 362 planes and a policy head.
Loss / Objective
The network fits search-improved policy targets and final game outcomes.
Sampling Rule
Training samples moves from root visit counts; evaluation plays greedily from the same counts.
Training Procedure
- Training steps:
- Mini-batch size:
- MCTS simulations per move:
- Learning rate:
- Dirichlet noise : chess , shogi , Go
- Self-play hardware: 5,000 first-generation TPUs
- Training hardware: 64 second-generation TPUs
- Separate network instance per game
Evaluation
Datasets
- Chess: 100-game match versus Stockfish 8
- Shogi: 100-game match versus Elmo WCSC27
- Go: 100-game match versus AlphaGo Zero 3-day
- Time control: 1 minute per move
Metrics
- Win / draw / loss over 100 games
- Elo during training
- Relative Elo versus thinking time
- Positions searched per second
Headline results
- Chess: 28 wins, 72 draws, 0 losses versus Stockfish.
- Shogi: 90 wins, 2 draws, 8 losses versus Elmo.
- Go: 52 wins, 48 losses versus AlphaGo Zero 3-day.
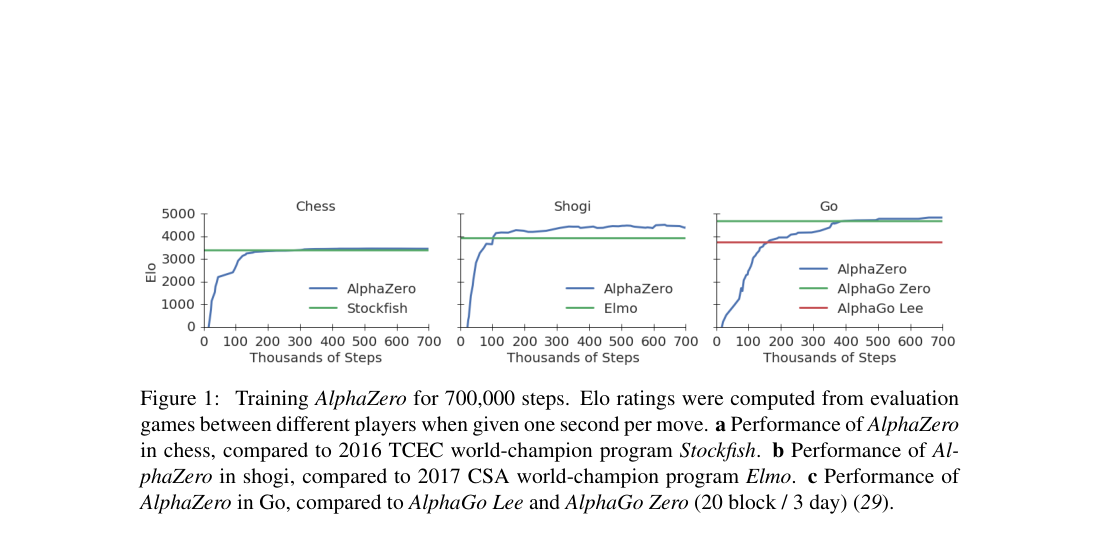
- Chess training: surpasses Stockfish after steps, about 4 hours.
- Shogi training: surpasses Elmo after steps, under 2 hours.
Table 1: Chess match results from the tournament evaluation table
| Game | White | Black | Win | Draw | Loss |
|---|---|---|---|---|---|
| Chess | AlphaZero | Stockfish | 25 | 25 | 0 |
| Chess | Stockfish | AlphaZero | 3 | 47 | 0 |
Ablations
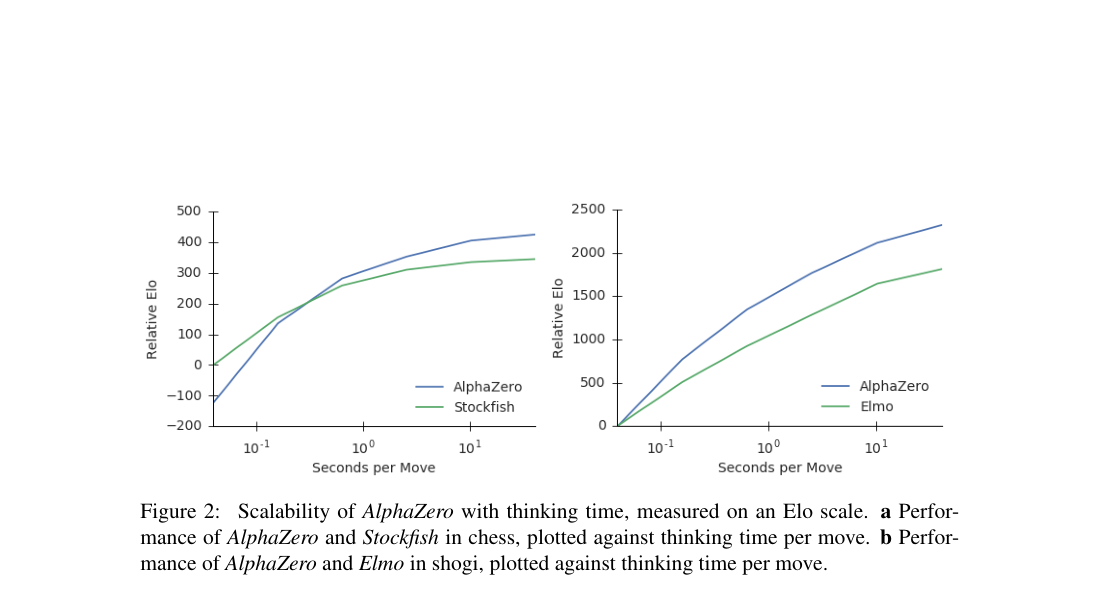
- Thinking time: AlphaZero gains Elo faster than Stockfish and Elmo as search time increases.
- Search efficiency: chess positions per second beats Stockfish at .
- Search efficiency: shogi positions per second beats Elmo at .
- Opening analysis: self-play rediscoveries cover the major human chess openings.
Method Strengths and Weaknesses
Strengths
- One algorithm works across chess, shogi, and Go with nearly shared hyperparameters.
- Beats Stockfish without a single loss in 100 tournament games.
- Beats Elmo decisively despite searching three orders fewer positions.
- Removes opening books, endgame tablebases, and handcrafted evaluation.
Weaknesses
- Training cost is extreme: 5,000 self-play TPUs and 64 training TPUs.
- Requires a separate training run for each game.
- Tournament evaluation uses only 100 games per opponent.
- Network-search internals remain less interpretable than alpha-beta heuristics.
Suggestions from the authors
- Add classical search-engine techniques to improve the pure self-play system.
- Test alternative board-state and action representations.
- Extend the approach beyond board games to other domains.
- Study which alpha-beta ideas still help inside the generic framework.
Links
Prior Papers
- @silverAlphaGo2016 — direct precursor: self-play policy-value learning with neural-guided search, specialised to Go.
Further Papers
- @christianoRLHF2017 — another self-play-era RL milestone, relevant to learned optimisation from feedback signals.
- @schulmanPPO2017 — a general RL baseline from the same period, useful for contrasting training regimes.