Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms
Problem
Framing
Vanilla policy gradients waste samples after one update, while TRPO stabilizes updates with a costly constrained solve. PPO closes this gap with a clipped surrogate that supports multiple minibatch epochs using first-order optimization. It reports 30/49 Atari wins by training-average reward.
Currently Used Methods
Foundational
- @mnihDQN2015 — deep Q-learning for discrete-control benchmarks.
- Limitation in context: weak on continuous control and not direct policy optimization.
- Trust Region Policy Optimization — KL-constrained surrogate optimization for stable policy updates.
- Limitation in context: conjugate-gradient machinery complicates implementation and scaling.
- High-Dimensional Continuous Control Using Generalized Advantage Estimation — variance-reduced advantage estimates for policy gradients.
- Limitation in context: repeated updates on one batch still destabilize learning.
- Asynchronous Methods for Deep Reinforcement Learning — scalable actor-critic baseline for Atari.
- Limitation in context: lower Atari sample efficiency than PPO in this comparison.
- Sample Efficient Actor-Critic with Experience Replay — strong replay-based Atari actor-critic baseline.
- Limitation in context: similar Atari performance with more algorithmic complexity.
Proposed Method
Architecture
PPO changes the update rule, not the network family. For MuJoCo, it uses separate policy and value MLPs with two 64-unit layers; the policy outputs Gaussian means with learned standard deviations. Shared policy-value parameters are also supported through a joint loss.
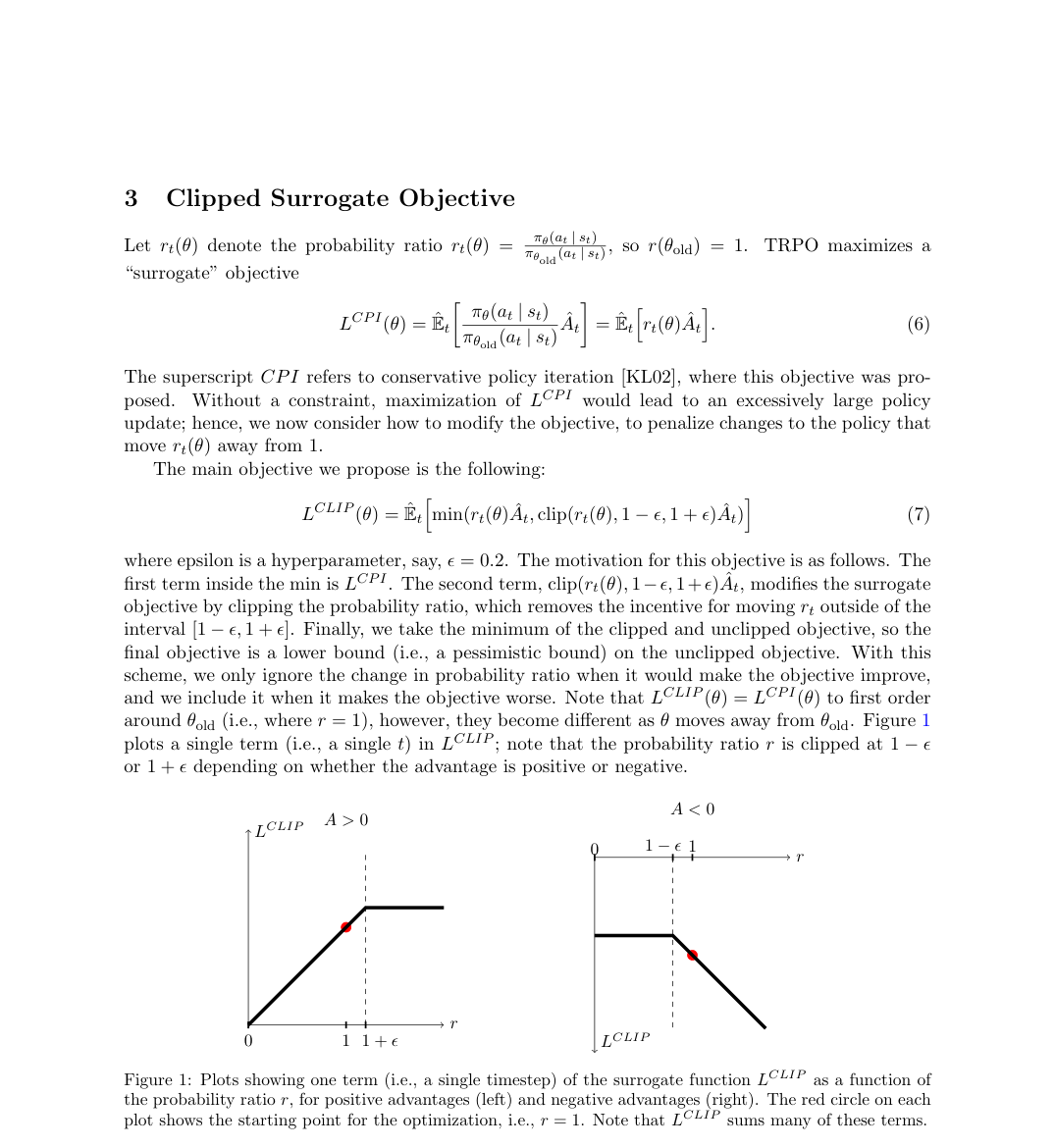
Loss / Objective
The core objective clips the probability ratio around the old policy.
Algorithm
PPO alternates rollout collection under with several epochs of minibatch ascent on the clipped surrogate.
Training Procedure
- MuJoCo horizon:
- MuJoCo Adam stepsize:
- MuJoCo epochs:
- MuJoCo minibatch size:
- MuJoCo discount:
- Atari horizon:
- Atari Adam stepsize:
- Atari epochs:
- Atari minibatch size:
- Atari discount:
Evaluation
Datasets
- OpenAI Gym MuJoCo: HalfCheetah-v1, Hopper-v1, InvertedDoublePendulum-v1, InvertedPendulum-v1, Reacher-v1, Swimmer-v1, Walker2d-v1
- Atari / Arcade Learning Environment
- RoboschoolHumanoidFlagrun qualitative control
Metrics
- Continuous control: average normalized score over 21 runs
- Atari: games won by average reward over all training
- Atari: games won by average reward over last 100 episodes
Headline results
- Continuous control, no clipping: avg. normalized score
- Continuous control, clipping : avg. normalized score
- Continuous control, best fixed-KL baseline (): avg. normalized score
- Atari, training-average criterion: PPO wins games; A2C , ACER
- Atari, last-100-episodes criterion: PPO wins games; A2C , ACER
Table 1: Atari game wins across summary criteria
| Criterion | A2C | ACER | PPO | Tie |
|---|---|---|---|---|
| (1) avg.episode reward over all of training | 1 | 18 | 30 | 0 |
| (2) avg.episode reward over last 100 episodes | 1 | 28 | 19 | 1 |
Ablations
- Clip range : beats and on the continuous benchmark.
- Remove clipping or KL penalty: performance drops below random-policy normalization.
- KL penalty, adaptive or fixed: both trail clipping.
- Clipping in log space: no gain over ratio clipping.
Method Strengths and Weaknesses
Strengths
- Clipped updates permit multiple minibatch epochs on one rollout batch.
- First-order optimization avoids TRPO's constrained second-order solve.
- Strong continuous-control result: normalized score at .
- Broad Atari sweep: 30/49 wins by training-average reward.
Weaknesses
- Final Atari performance trails ACER on last-100-episode reward, 19 wins versus 28.
- Performance depends on clip range; underperforms .
- Clipping is heuristic, not a hard trust-region guarantee.
- Paper emphasizes online updates, not replay-heavy sample reuse.
Suggestions from the authors
- Analyze stronger theory for the clipped surrogate.
- Test broader architectures with parameter sharing and stochastic components.
- Extend comparisons beyond Atari and standard locomotion tasks.
- Study simpler KL-control variants that retain performance.
Links
Prior Papers
- @mnihDQN2015 — canonical deep RL baseline for the Atari comparisons.
- @christianoRLHF2017 — later preference-based RL pipelines adopt PPO-style policy optimization.
- @silverAlphaZero2018 — large-scale policy optimization in RL makes PPO a useful practical comparator.
Further Papers
- @christianoRLHF2017 — preference-based RL commonly uses PPO as the policy-update backbone.
- @ouyangInstructGPT2022 — RLHF for language models uses PPO for reward-model optimization.