Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models
Problem
Framing
Language-model scaling lacked a quantitative law linking loss to parameters, data, and compute. The paper shows cross-entropy follows stable power laws in , , and compute, then uses them to derive compute-optimal training that favors larger models and early stopping.
Currently Used Methods
Foundational
- @vaswaniAttentionAllNeed2017 — Transformer self-attention backbone for autoregressive language modeling.
- Limitation in context: gives architecture, not predictive loss laws versus scale.
- @radfordGPT2_2019 — large decoder-only pretraining on WebText.
- Limitation in context: shows scale helps, without compute-allocation equations.
- Characterizing Well-Performing Neural Network Architectures — gradient-noise-scale analysis for efficient batch sizing.
- Limitation in context: studies optimization efficiency, not joint scaling in , , and .
- Generating Wikipedia by Summarizing Long Sequences — recurrent alternatives for long-context language modeling.
- Limitation in context: architecture choice matters less than total scale here.
Proposed Method
Architecture
The paper introduces no new block. It studies decoder-only Transformers on WebText2 with context and measures scale by non-embedding parameters .
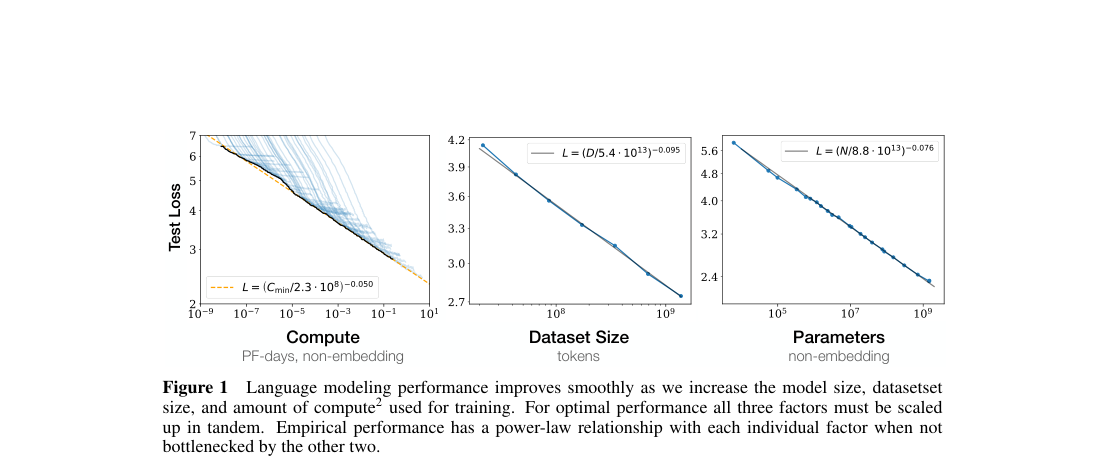
Loss / Objective
The core model is a fitted scaling law for autoregressive cross-entropy.
Sampling Rule / Algorithm
Training compute is approximated from parameters, batch size, and optimization steps.
Training Procedure
- Dataset: WebText2
- Tokenization: BPE,
- Context length:
- Steps:
- Batch size: sequences of length
- Optimizer: Adam
- Optimizer for B models: Adafactor
- Dropout:
- Model sizes: to non-embedding parameters
- Dataset sizes: to tokens
Evaluation
Datasets
- WebText2 test
- Internet Books
- Common Crawl
- Wikipedia
Metrics
- Cross-entropy loss in nats
- Test loss versus , , and compute
- Transfer-loss offset across distributions
- Critical batch size in tokens
Headline results
- Parameter-limited: , .
- Dataset-limited: , tokens.
- Compute-optimal frontier: , PF-days.
- Overfitting boundary: penalty scales with .
- Largest converged runs: critical batch size reaches roughly - million tokens.
Table 1: Fit to
| Parameter | |||
|---|---|---|---|
| Value | 0.076 | 0.103 |
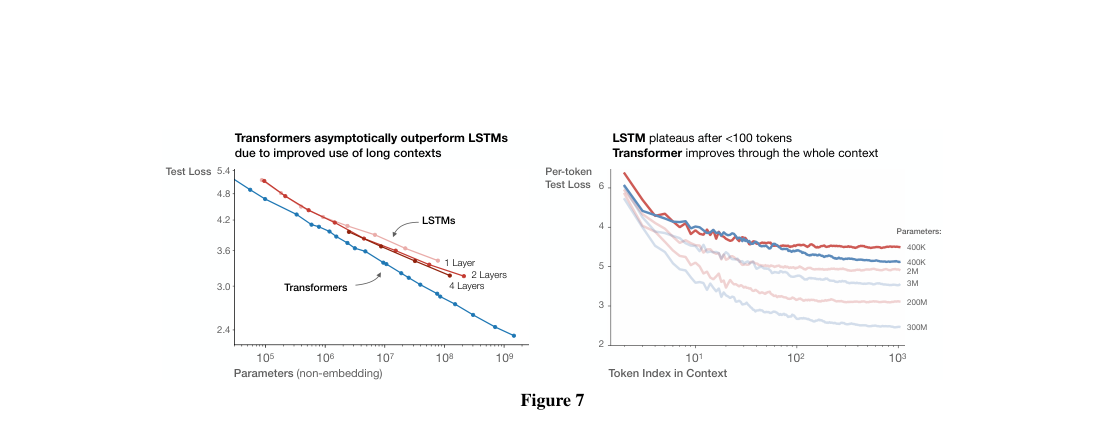
Ablations
- Width versus depth: loss changes little at fixed total parameter count.
- Early-curve extrapolation: later loss is predictable from the stable training regime.
- Transfer evaluation: out-of-domain loss differs by an almost constant offset.
- Batch-size sweep: critical batch size follows a power law in loss.
Method Strengths and Weaknesses
Strengths
- Gives closed-form loss laws across parameters, data, and compute.
- Trends span more than six orders of magnitude.
- Converts descriptive scaling into compute-allocation rules.
- Shows model shape has weak effect once scale is fixed.
Weaknesses
- Focuses on cross-entropy, not downstream task accuracy.
- Constants depend on dataset, tokenization, and vocabulary.
- Largest models stop at B parameters.
- Compute-optimal advice relies on extrapolated large-scale behavior.
Suggestions from the authors
- Test whether the same exponents persist at larger model scales.
- Measure scaling under different datasets and tokenizations.
- Extend the analysis to other modalities and objectives.
- Probe batch-size behavior farther beyond the measured regime.
Links
Prior Papers
- @radfordGPT2_2019 — establishes the large decoder-only language-model regime this paper turns into explicit scaling laws.
- @vaswaniAttentionAllNeed2017 — provides the Transformer backbone whose size and shape are varied in the study.
Further Papers
- @brownGPT3_2020 — scales autoregressive language models into the regime anticipated by these power laws.
- @hoffmannChinchilla2022 — revises compute-optimal scaling by allocating more budget to data.