Training Compute-Optimal Large Language Models
Training Compute-Optimal Large Language Models
Problem
Framing
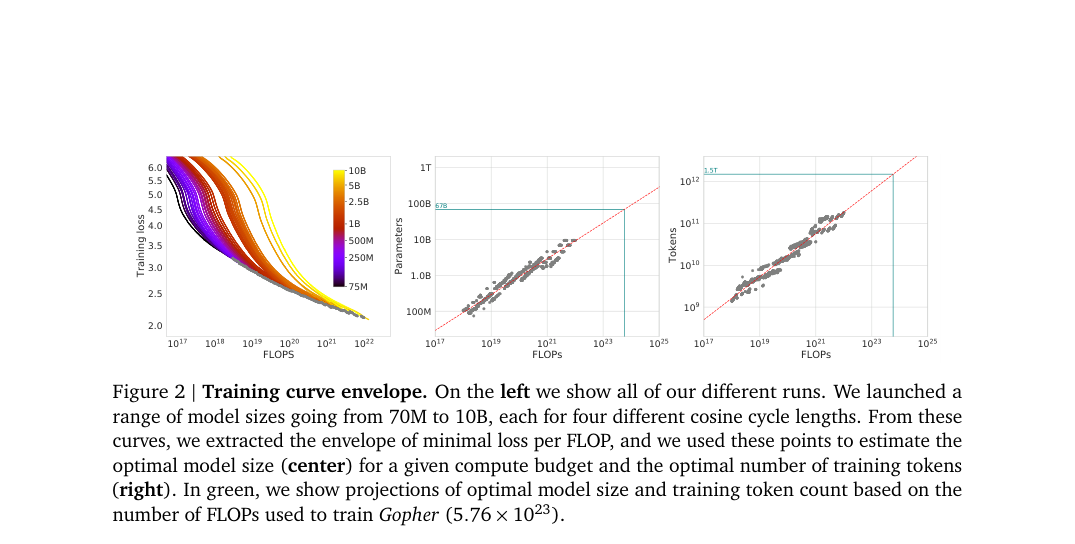
Kaplan-style scaling laws over-allocate compute to parameters and under-allocate it to data. The paper refits the compute frontier and shows that optimal training scales parameters and tokens nearly equally. At Gopher compute, this shifts the target from 280B parameters to about 70B trained on 1.4T tokens.
Currently Used Methods
Foundational
- @brownGPT3_2020 — 175B dense LM proves few-shot gains at scale.
- Limitation in context: trained on too few tokens for its compute budget.
- @kaplanScalingLaws2020 — power-law loss scaling versus parameters, data, and compute.
- Limitation in context: compute rule favors oversized models and short training.
- @radfordGPT2_2019 — decoder-only scaling shows broad zero-shot transfer.
- Limitation in context: offers no compute-optimal parameter-token prescription.
- Gopher — 280B decoder-only baseline with broad downstream evaluation.
- Limitation in context: same FLOPs train a smaller model longer with lower loss.
Proposed Method
Architecture
Chinchilla keeps the Gopher decoder-only transformer and changes scale, not design. The main model uses 80 layers, , 64 heads, key/value size 128, and feed-forward width .
Loss / Objective
The analysis fits final pretraining loss as separate penalties for finite model size and finite data.
Sampling Rule / Algorithm
Compute-optimal allocation minimizes the fitted loss under the transformer training-cost constraint.
Training Procedure
- Dataset: MassiveText.
- Optimizer: AdamW.
- Model: 70B decoder-only transformer.
- Layers: 80.
- Heads: 64.
- : 8192.
- Key/value size: 128.
- Feed-forward width: .
- Max learning rate: .
- Batch size: M M tokens.
- Training tokens: T.
- LR schedule: cosine with decay.
Evaluation
Datasets
- Training: MassiveText.
- Language modeling: WikiText-103, The Pile subsets, PG-19, arXiv, FreeLaw.
- Reading comprehension: RACE-m, RACE-h, LAMBADA.
- Question answering: Natural Questions, TriviaQA, TruthfulQA.
- Common sense: HellaSwag, Winogrande, PIQA, SIQA, BoolQ.
- Language understanding: MMLU, BIG-bench.
Metrics
- Pretraining loss.
- Bits per byte.
- Accuracy.
- Exact match.
- Group-stratified accuracy on Winogender.
Headline results
- Gopher-compute regime: 70B on 1.4T tokens beats 280B Gopher.
- MMLU (5-shot): .
- BIG-bench, 62 tasks: .
- LAMBADA (zero-shot): .
- RACE-m (few-shot): .
- Natural Questions (64-shot): .
Ablations
- Model size vs tokens: IsoFLOP curves show a clear loss-minimizing valley.
- Frontier estimation: three fitting methods recover near-equal parameter and token scaling.
- Cosine cycle length: overshooting target steps hurts final loss.
- Optimizer choice: AdamW finishes better than Adam.
Method Strengths and Weaknesses
Strengths
- Recasts scaling as constrained optimization over parameters and tokens.
- Uses 400+ runs instead of one extrapolated frontier fit.
- Delivers better downstream accuracy than Gopher with one quarter the parameters.
- Three estimation routes agree on near- scaling.
Weaknesses
- Main prescription depends on the fit .
- Analysis models data quantity directly, not data quality.
- Validation targets dense decoder-only transformers, not broader architectures.
- Winogender group gaps remain despite higher overall accuracy.
Suggestions from the authors
- Scale datasets further without degrading data quality.
- Test richer loss models beyond simple power-law fits.
- Extend compute-optimal analysis beyond dense transformers.
- Improve large-scale data collection for long-training regimes.
Links
Prior Papers
- @brownGPT3_2020 — Chinchilla revises the GPT-3-era parameter-versus-token allocation.
- @kaplanScalingLaws2020 — the paper directly corrects Kaplan compute-optimal prescriptions.
- @radfordGPT2_2019 — it inherits the decoder-only scaling line and sharpens its training-allocation rule.
Further Papers
- @ouyangInstructGPT2022 — instruction tuning benefits from stronger pretrained bases under fixed compute.
- @alayracFlamingo2022 — multimodal scaling faces the same compute-allocation tradeoff between capacity and data.
- @dettmersQLoRA2023 — efficient adaptation makes compute-optimal pretrained backbones more practically useful.