QLoRA: Efficient Finetuning of Quantized LLMs
QLoRA: Efficient Finetuning of Quantized LLMs
Problem
Framing
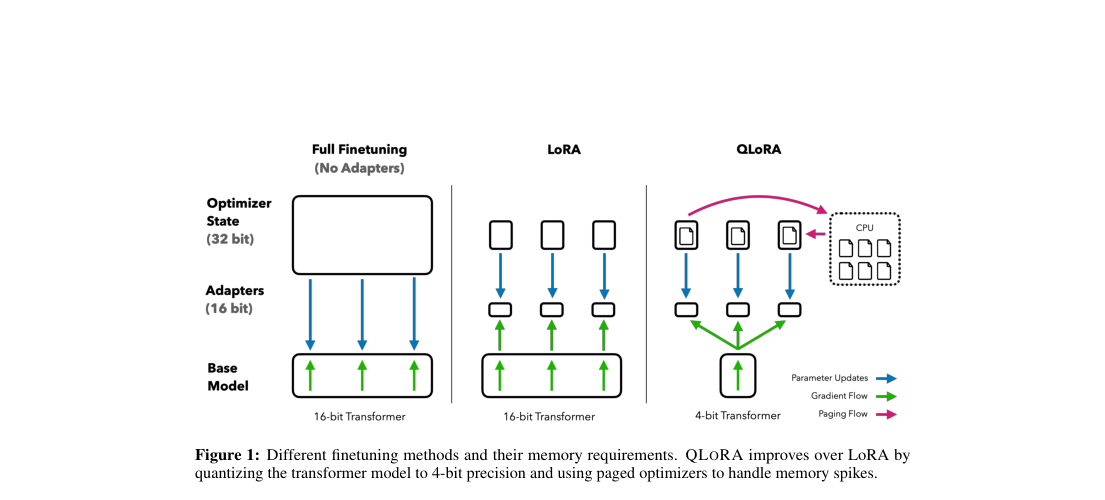
Finetuning 33B–65B LLMs is memory-bound: 16-bit tuning of LLaMA-65B needs more than 780 GB, and inference quantizers fail under backpropagation. QLoRA closes this gap by freezing a 4-bit base model, training LoRA adapters through dequantized weights, and fitting 65B finetuning under 48 GB without losing reported 16-bit task performance.
Currently Used Methods
Foundational
- @huLoRA2021 — low-rank adapters for parameter-efficient finetuning.
- Limitation in context: base weights stay higher precision, so memory still scales poorly.
- LLM.int8() — 8-bit quantization that preserves LLM inference quality.
- Limitation in context: designed for inference; training through quantized weights breaks down.
- SmoothQuant — activation-weight rescaling for low-bit inference.
- Limitation in context: does not provide stable 4-bit finetuning.
- Full 16-bit finetuning — updates all pretrained parameters directly.
- Limitation in context: 65B-scale memory exceeds single-GPU budgets.
- Query/key-only LoRA placement — sparse adapter insertion in attention blocks.
- Limitation in context: leaves measurable accuracy gaps versus full finetuning.
Proposed Method
Architecture
QLoRA stores the pretrained transformer in 4-bit NF4, dequantizes weights to BF16 for compute, and trains only LoRA adapters. It adds double-quantized scaling constants and paged optimizers, and places adapters in all layers to recover full-finetuning accuracy.
Loss / Objective
The trainable map is the LoRA-augmented frozen linear layer.
Quantization Rule
NF4 chooses levels from normal-distribution quantiles, then computes with doubly dequantized frozen weights.
Training Procedure
- Base weights: frozen 4-bit NF4.
- Quantization constants: FP8 under double quantization.
- Weight block size: 64.
- Quantization-constant block size: 256.
- LoRA dropout search: .
- LoRA rank search: .
- LoRA layer search: key+query, all attention, all FFN, all layers, attention+FFN outputs.
- Guanaco 7B example: batch size 16, learning rate .
Evaluation
Datasets
- GLUE with RoBERTa-large.
- Super-NaturalInstructions with T5-80M to T5-11B.
- 5-shot MMLU after LLaMA finetuning on FLAN v2 and Alpaca.
- Vicuna prompts for chatbot tournaments.
- OASST1 validation prompts for chatbot evaluation.
Metrics
- Accuracy on GLUE.
- RougeL on Super-NaturalInstructions.
- 5-shot accuracy on MMLU.
- Elo from GPT-4 and human pairwise judgments.
- GPU memory footprint in GB.
Headline results
- LLaMA-65B finetuning: memory drops from GB to GB.
- Vicuna benchmark: Guanaco 65B reaches of ChatGPT.
- Vicuna benchmark: Guanaco 33B reaches of ChatGPT.
- GPT-4 Elo tournament: Guanaco 65B scores ; ChatGPT scores .
- MMLU datatype study: NF4 + DQ matches BF16; FP4 trails by about 1 point.
Table 1: Mean zero-shot accuracy over tasks and model scales for 4-bit LLaMA variants
| Data type |
|---|
| Float |
| NF4 |
| NF4 + DQ |
Ablations
- Data type: NF4 outperforms FP4 and tracks BF16 across MMLU settings.
- Double quantization: saves about bits per parameter with no reported loss.
- Adapter placement: all-layer LoRA is needed to match 16-bit finetuning.
- Dataset choice: OASST1 9k beats a 450k FLAN v2 subset for chatbot quality.
Method Strengths and Weaknesses
Strengths
- Finetunes 65B models on one 48 GB GPU.
- Matches reported 16-bit performance on GLUE, T5, and MMLU studies.
- NF4 improves 4-bit accuracy over FP4 baselines.
- All-layer adapters remove major LoRA accuracy gaps.
Weaknesses
- No direct 33B or 65B comparison against full 16-bit finetuning.
- Chatbot rankings rely on noisy GPT-4 and human preference judgments.
- GPT-4 and human rankings disagree at both system and example levels.
- Guanaco inherits bias and failure modes from the base model.
Suggestions from the authors
- Test whether QLoRA matches full 16-bit finetuning at 33B and 65B.
- Study 3-bit bases and alternative PEFT methods beyond LoRA.
- Improve benchmark reliability for chatbot evaluation.
- Analyze failure cases and inherited biases more systematically.
Links
Prior Papers
- @huLoRA2021 — QLoRA keeps LoRA adapters but moves the frozen base model into 4-bit training.
Further Papers
No vault papers identified as further work yet.