LoRA: Low-Rank Adaptation of Large Language Models
LoRA: Low-Rank Adaptation of Large Language Models
Problem
Framing
Full fine-tuning of 100B-scale language models duplicates nearly all weights per task, making storage and optimization expensive. LoRA closes this gap by freezing the backbone and learning low-rank updates inside Transformer projections, matching or beating full tuning with up to fewer trainable parameters.
Currently Used Methods
Direct antecedents
- @brownGPT3_2020 — 175B autoregressive LM that makes adaptation operationally costly.
- Limitation in context: standard tuning still duplicates the full checkpoint.
- @devlinBERT2018 — pretrain-then-fine-tune paradigm for downstream NLP.
- Limitation in context: full updates remain memory-heavy at large scale.
- @vaswaniAttentionAllNeed2017 — Transformer with dense attention projection matrices.
- Limitation in context: offers no parameter-efficient adaptation rule.
- "Prefix-Tuning: Optimizing Continuous Prompts for Generation" — tunes continuous prompts instead of backbone weights.
- Limitation in context: uses sequence length and degrades when prompt budgets grow.
- "Parameter-Efficient Transfer Learning for NLP" — inserts adapter bottlenecks between Transformer blocks.
- Limitation in context: added layers keep inference slower than merged weight updates.
Proposed Method
Architecture
LoRA freezes each pretrained matrix and learns a low-rank update with , , and . The paper applies LoRA mainly to self-attention projections, especially and , and merges into at inference.
Loss / Objective
The downstream objective stays the standard conditional language-model objective under the LoRA reparameterization.
Algorithm
Each adapted layer adds a scaled low-rank residual to the frozen linear map.
Training Procedure
- Initialize with Gaussian noise.
- Initialize to zero.
- Scale updates by .
- Freeze pretrained weights .
- GPT-3: AdamW, batch size , epochs, warmup tokens .
- GPT-2: AdamW, linear schedule, epochs.
- GLUE: AdamW, linear schedule, warmup ratio or .
Evaluation
Datasets
- GLUE with RoBERTa base/large and DeBERTa XXL.
- E2E, WebNLG, DART with GPT-2.
- WikiSQL, MultiNLI-m, SAMSum with GPT-3 175B.
Metrics
- Accuracy for GLUE, WikiSQL, MultiNLI.
- ROUGE-1/2/L for SAMSum.
- BLEU, NIST, METEOR, ROUGE-L, CIDEr for E2E.
- METEOR and TER for WebNLG and DART.
- Forward latency for GPT-2.
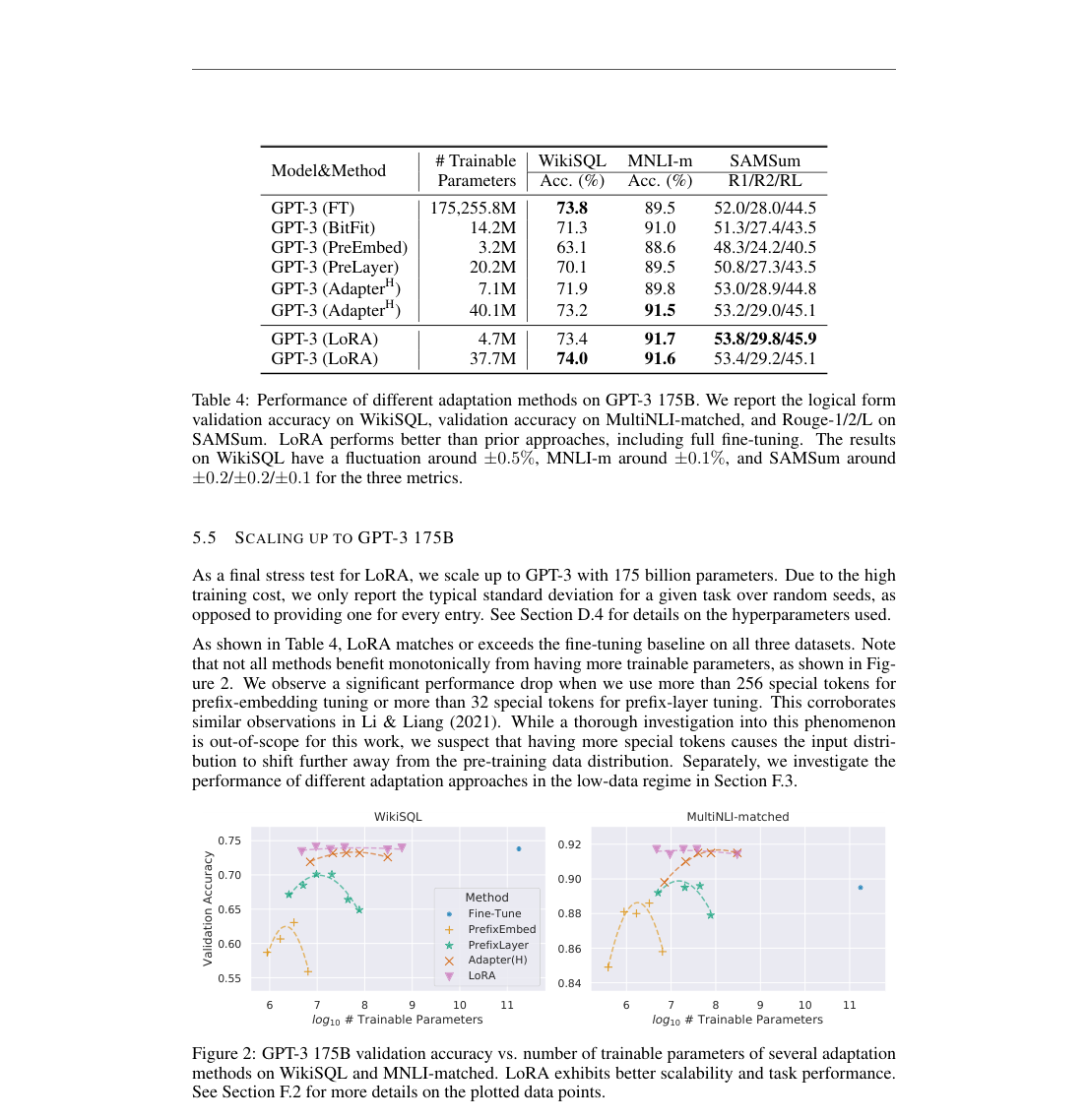
Headline results
- GLUE, RoBERTa base: average with M trainable parameters.
- GPT-3 175B, WikiSQL: with M LoRA parameters; with M.
- GPT-3 175B, MultiNLI-m: with LoRA vs. full fine-tuning.
- GPT-3 175B, SAMSum: ROUGE-1/2/L vs. full fine-tuning.
- GPT-2 medium latency: LoRA matches fine-tuning latency; adapters add overhead.
Table 4: Performance of different adaptation methods on GPT-3 175B
| Model&Method | # Trainable Parameters | WikiSQL Acc. (%) | MNLI-m Acc.(%) | SAMSum R1/R2/RL |
|---|---|---|---|---|
| GPT-3 (FT) | 175,255.8M | 73.8 | 89.5 | 52.0/28.0/44.5 |
| GPT-3 (BitFit) | 14.2M | 71.3 | 91.0 | 51.3/27.4/43.5 |
| GPT-3 (PreEmbed) | 3.2M | 63.1 | 88.6 | 48.3/24.2/40.5 |
| GPT-3 (PreLayer) | 20.2M | 70.1 | 89.5 | 50.8/27.3/43.5 |
| GPT-3 (Adapter) | 7.1M | 71.9 | 89.8 | 53.0/28.9/44.8 |
| GPT-3 (Adapter) | 40.1M | 73.2 | 91.5 | 53.2/29.0/45.1 |
| GPT-3 (LoRA) | 4.7M | 73.4 | 91.7 | 53.8/29.8/45.9 |
| GPT-3 (LoRA) | 37.7M | 74.0 | 91.6 | 53.4/29.2/45.1 |
Ablations
- Weight choice: adapting and beats only or only at fixed budget.
- Rank : even stays competitive on WikiSQL and MultiNLI.
- Parameter scaling: LoRA stays strong as trainable parameters increase; prefix methods deteriorate.
- Correlation study: amplifies useful directions already present but underemphasized in .
Method Strengths and Weaknesses
Strengths
- Matches or beats full fine-tuning on GPT-3 175B tasks.
- Cuts trainable parameters by up to .
- Merges into base weights, so inference latency stays unchanged.
- Very small ranks already work on multiple tasks.
Weaknesses
- Weight-matrix selection is mostly heuristic.
- Main evidence centers on attention projections, not all dense layers.
- Small-rank success is tested on modest task shifts.
- Benefits depend on useful directions already existing in pretrained weights.
Suggestions from the authors
- Combine LoRA with other efficient adaptation methods.
- Explain how pretrained features transform during LoRA adaptation.
- Find principled rules for selecting target weight matrices.
- Test whether pretrained weights themselves are rank-deficient.
Links
Prior Papers
- @brownGPT3_2020 — Supplies the large-model regime where full fine-tuning becomes costly.
- @devlinBERT2018 — Establishes the pretrain-then-fine-tune setup that LoRA makes cheaper.
- @vaswaniAttentionAllNeed2017 — Defines the Transformer projection matrices that LoRA reparameterizes.
Further Papers
- @dettmersQLoRA2023 — Extends LoRA with quantization to further reduce memory for LLM adaptation.