Flamingo: a Visual Language Model for Few-Shot Learning
Flamingo: a Visual Language Model for Few-Shot Learning
Problem
Framing
Few-shot vision-language systems either score image-text compatibility or need task-specific fine-tuning. Flamingo closes this gap by inserting lightweight visual conditioning into a frozen LM, so one prompted model handles interleaved images, videos, and text. It reports best zero/few-shot results on all 16 evaluated benchmarks.
Currently Used Methods
Foundational
- @radfordCLIP2021 — contrastive image-text pretraining for zero-shot recognition.
- Limitation in context: ranks labels or captions, but cannot generate open-ended answers.
- @brownGPT3_2020 — in-context learning with large autoregressive language models.
- Limitation in context: text-only interface cannot condition on images or videos.
- SimVLM: Simple Visual Language Model Pretraining with Weak Supervision — visually conditioned language generation at scale.
- Limitation in context: weaker few-shot transfer across diverse multimodal benchmarks.
- OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework — unified seq2seq modeling across vision-language tasks.
- Limitation in context: stronger supervised transfer than prompted low-shot adaptation.
- Florence: A New Foundation Model for Computer Vision — large-scale multimodal pretraining with broad transfer.
- Limitation in context: still trails Flamingo on few-shot prompted evaluation.
Proposed Method
Architecture
Flamingo freezes a vision encoder and a causal LM, then adds a Perceiver Resampler plus interleaved GATED XATTN-DENSE blocks. Each image or video is compressed to a fixed latent set, and each text token attends only to the most recent visual input.
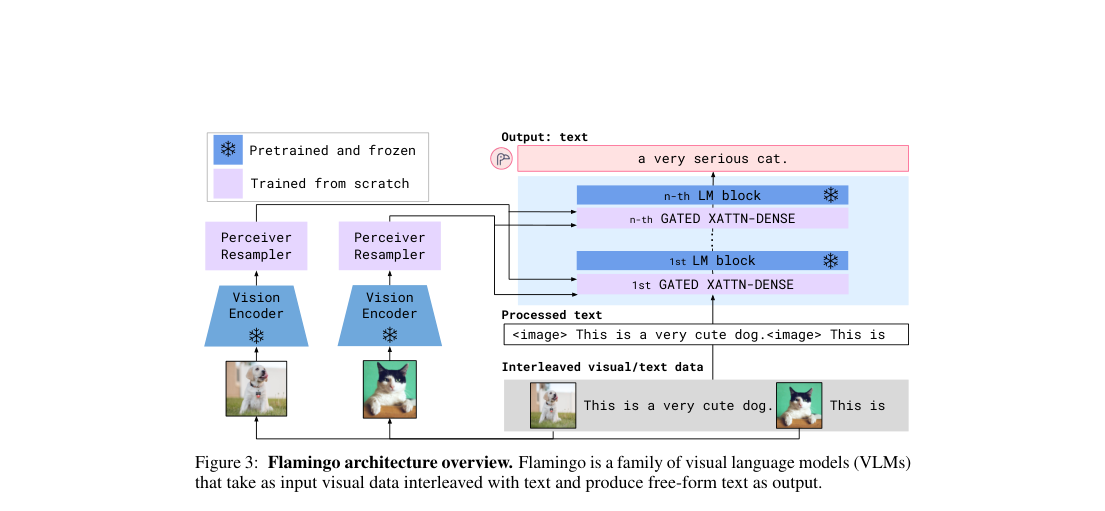
Loss / Objective
Training is autoregressive next-token prediction over interleaved visual-text sequences.
Algorithm
Visual features enter the frozen LM through gated cross-attention and gated feed-forward residuals.
Training Procedure
- Optimizer: AdamW.
- Gradient clipping: global norm .
- Weight decay: on Resampler, elsewhere.
- Learning rate: linear warmup to over steps, then constant.
- Ablation batch sizes: M3W , ALIGN , LTIP , VTP .
- Ablation schedule: gradient-calculation steps.
Evaluation
Datasets
- 16 multimodal benchmarks.
- DEV: COCO, OKVQA, VQAv2, MSVDQA, VATEX.
- Held-out: VizWiz, MSRVTTQA, VisDial, YouCook2, TextVQA, HatefulMemes, iVQA, NextQA, Flickr30k, RareAct, STAR.
Metrics
- CIDEr for captioning.
- Top-1 accuracy for VQA and classification-style tasks.
- Recall@K for retrieval.
- Aggregated score: task score divided by task SotA, then averaged.
Headline results
- 16-task suite, zero/few-shot: best previous zero/few-shot method on all 16 tasks.
- 16-task suite, 32-shot: beats fine-tuned SotA on 6 tasks.
- VQAv2 test-dev (32-shot): .
- COCO test CIDEr (32-shot): .
- VATEX test CIDEr (32-shot): .
- HatefulMemes seen test (32-shot): .
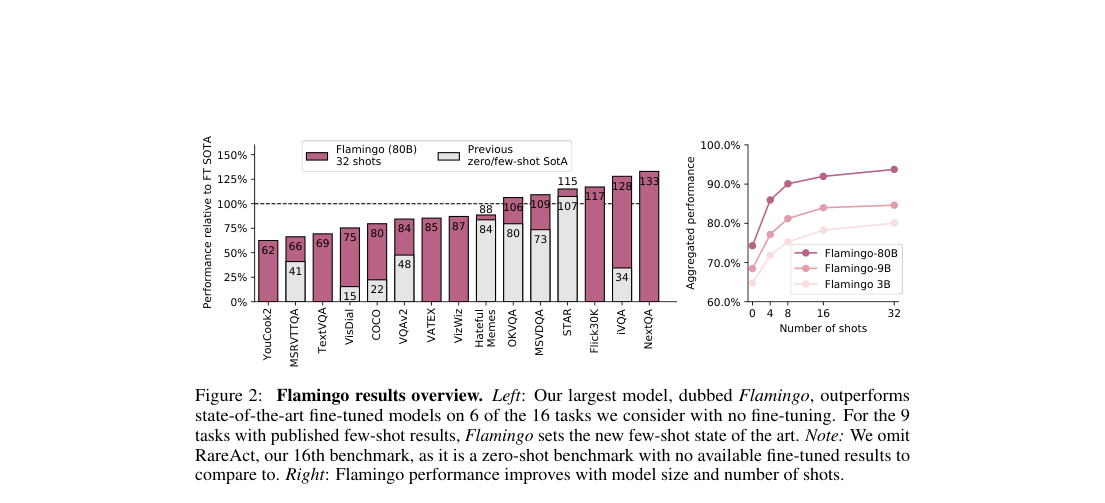
Table 3: Flamingo-3B ablations on five DEV benchmarks with 4 shots
| Ablated setting | Flamingo-3B original value | Changed value | Param.count | Step time | COCO CIDEr | OKVQA top1 | VQAv2 top1 | MSVDQA top1 | VATEX CIDEr | Overall score |
|---|---|---|---|---|---|---|---|---|---|---|
| Flamingo-3B model | 3.2B | 1.74s | 86.5 | 42.1 | 55.8 | 36.3 | 53.4 | 70.7 | ||
| (i) Training data | All data | w/o Video-Text pairs | 3.2B | 1.42s | 84.2 | 43.0 | 53.9 | 34.5 | 46.0 | 67.3 |
| w/o Image-Text pairs | 3.2B | 0.95s | 66.3 | 39.2 | 51.6 | 32.0 | 41.6 | 60.9 | ||
| Image-Text pairs LAION | 3.2B | 1.74s | 79.5 | 41.4 | 53.5 | 33.9 | 47.6 | 66.4 | ||
| w/o M3W | 3.2B | 1.02s | 54.1 | 36.5 | 52.7 | 31.4 | 23.5 | 53.4 | ||
| (ii) Optimisation | Accumulation | Round Robin | 3.2B | 1.68s | 76.1 | 39.8 | 52.1 | 33.2 | 40.8 | 62.9 |
| (iii) Tanh gating | 3 | 7 | 3.2B | 1.74s | 78.4 | 40.5 | 52.9 | 35.9 | 47.5 | 66.5 |
| (iv) Cross-attention architecture | GATED XATTN - DENSE | VANILLA XATTN | 2.4B | 1.16s | 80.6 | 41.5 | 53.4 | 32.9 | 50.7 | 66.9 |
| GRAFTING | 3.3B | 1.74s | 79.2 | 36.1 | 50.8 | 32.2 | 47.8 | 63.1 | ||
| (v) Cross-attention frequency | Every | Single in middle | 2.0B | 0.87s | 71.5 | 38.1 | 50.2 | 29.1 | 42.3 | 59.8 |
| Every 4th | 2.3B | 1.02s | 82.3 | 42.7 | 55.1 | 34.6 | 50.8 | 68.8 | ||
| Every 2nd | 2.6B | 1.24s | 83.7 | 41.0 | 55.8 | 34.5 | 49.7 | 68.2 | ||
| (vi) Resampler | Perceiver | MLP | 3.2B | 1.85s | 78.6 | 42.2 | 54.7 | 35.2 | 44.7 | 66.6 |
| Transformer | 3.2B | 1.81s | 83.2 | 41.7 | 55.6 | 31.5 | 48.3 | 66.7 | ||
| (vii) Vision encoder | NFNet-F6 | CLIP ViT-L/14 | 3.1B | 1.58s | 76.5 | 41.6 | 53.4 | 33.2 | 44.5 | 64.9 |
| NFNet-F0 | 2.9B | 1.45s | 73.8 | 40.5 | 52.8 | 31.1 | 42.9 | 62.7 | ||
| (viii) Freezing LM | 3 | 7 (random init) | 3.2B | 2.42s | 74.8 | 31.5 | 45.6 | 26.9 | 50.1 | 57.8 |
| 7 (pretrained) | 3.2B | 2.42s | 81.2 | 33.7 | 47.4 | 31.0 | 53.9 | 62.7 |
Ablations
- Training data: removing M3W drops overall score from to .
- Tanh gating: removing the default gated design drops overall score by .
- Cross-attention frequency: every 4th block cuts training time from s to s for small score loss.
- Vision encoder: NFNet-F6 beats CLIP ViT-L/14 by overall.
Method Strengths and Weaknesses
Strengths
- One prompted model sets zero/few-shot SotA on 16 benchmarks.
- Beats fine-tuned SotA on 6 tasks with only 32 examples.
- Freezing the LM avoids catastrophic forgetting during multimodal training.
- Perceiver Resampler supports variable-resolution images and videos.
Weaknesses
- Performance is highly sensitive to the training data mixture.
- Best results require very large models, up to 80B parameters.
- Dense cross-attention insertion increases trainable parameters and step time.
- Few-shot Flamingo still trails full fine-tuning on several benchmarks.
Suggestions from the authors
- Improve multimodal data mixture design and weighting.
- Better disambiguate multiple previous images during cross-attention.
- Study optimization effects of inserted conditioning layers.
- Explore cheaper cross-attention schedules across LM depth.
Links
Prior Papers
- @brownGPT3_2020 — Flamingo extends GPT-style in-context learning to interleaved visual-text prompts.
- @radfordCLIP2021 — Flamingo builds on large-scale image-text pretraining but replaces contrastive scoring with generation.
- @rameshDALLE2021 — both couple visual representations with autoregressive language-style generation.
- @liuSwinTransformer2021 — relevant vision-backbone precursor for large-scale multimodal systems.
Further Papers
- @liBLIP2_2023 — another frozen-backbone bridge from pretrained vision encoders to large language models.
- @rombachLatentDiffusion2022 — relevant vault follow-on for multimodal conditioning and foundation-model interfaces.