BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Problem
Framing
End-to-end vision-language pre-training scales poorly once both the vision tower and LLM are large. BLIP-2 closes this with a lightweight Q-Former that queries frozen image features and emits LLM-compatible tokens. It reports 65.0 zero-shot VQAv2 with 188M trainable parameters.
Currently Used Methods
Direct antecedents
- @radfordCLIP2021 — aligned image-text embeddings from large-scale contrastive pre-training.
- Limitation in context: no generative interface to a frozen LLM.
- @alayracFlamingo2022 — frozen backbones with cross-attention for multimodal prompting.
- Limitation in context: needs far more trainable bridging parameters.
- "DALL·E: Zero-Shot Text-to-Image Generation" — large-scale vision-language pre-training for generation.
- Limitation in context: not a frozen-LLM image-to-text bridge.
- "BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation" — unified VLP objectives for understanding and generation.
- Limitation in context: does not target frozen-backbone bootstrapping.
Proposed Method
Architecture
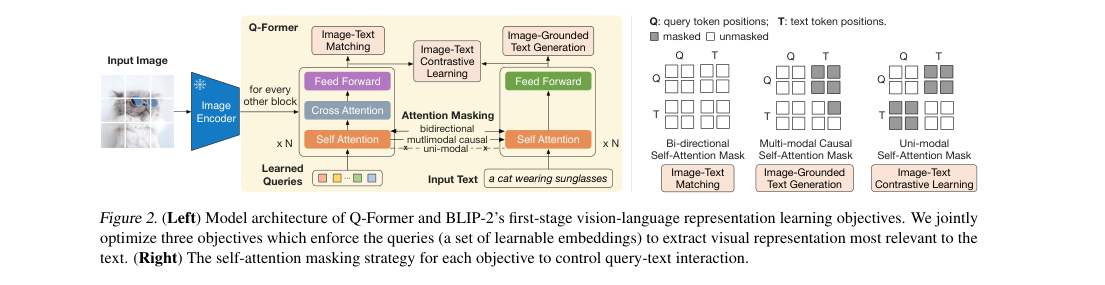
BLIP-2 has three parts: a frozen image encoder, a Q-Former, and a frozen LLM. Q-Former uses 32 learned queries, hidden width 768, BERTbase initialization, and cross-attention inserted every other block. A linear projection maps query outputs into the chosen LLM embedding space.
Loss / Objective
Stage 1 learns query features with contrastive, matching, and grounded generation losses. Stage 2 trains only language modeling over projected query outputs.
Algorithm
The connector first queries frozen vision features, then projects them into the frozen LLM token space.
Training Procedure
- Learned queries: 32
- Query width: 768
- Trainable module size: 188M
- Q-Former init: BERTbase
- Cross-attention: every other block
- Fine-tuning epochs: 5
- Warmup steps: 1000
- Learning rate: for LLM-side fine-tuning
- Image-encoder fine-tuning learning rate: to
Evaluation
Datasets
- VQAv2
- OK-VQA
- GQA
- NoCaps
- COCO Caption
- Flickr30K
Metrics
- VQA accuracy
- CIDEr
- SPICE
- BLEU@4
- Recall@1
Headline results
- VQAv2 zero-shot (test-dev): 65.0 accuracy
- OK-VQA zero-shot (test): 45.9 accuracy
- GQA zero-shot (test-dev): 44.7 accuracy
- NoCaps zero-shot (val): 121.6 CIDEr, 15.8 SPICE
- Flickr30K zero-shot (test): 97.6 TR@1, 89.7 IR@1
Ablations
- Image encoder scale: ViT-g beats ViT-L across OPT and FlanT5 variants.
- LLM scale: larger OPT and FlanT5 models improve zero-shot VQA.
- LLM family: FlanT5 beats OPT on VQA at similar visual backbones.
- Stage-1 objectives: removing representation learning hurts downstream transfer.
Method Strengths and Weaknesses
Strengths
- Freezes both backbones yet reaches 65.0 zero-shot VQAv2.
- Uses only 188M trainable parameters for multimodal bootstrapping.
- Works with decoder-only OPT and encoder-decoder FlanT5.
- Strong zero-shot retrieval: 97.6 TR@1 and 89.7 IR@1 on Flickr30K.
Weaknesses
- Few-shot in-context learning remains weak.
- Training depends on three hand-designed stage-1 objectives.
- Performance rises with larger vision and language backbones.
- Q-Former is still a substantial 188M-parameter connector.
Suggestions from the authors
- Improve few-shot in-context learning with stronger multimodal prompting.
- Better exploit stronger pretrained image encoders.
- Better exploit stronger instruction-tuned LLMs.
- Design better alignment objectives for frozen vision-language bootstrapping.
Links
Prior Papers
- @radfordCLIP2021 — CLIP supplies the frozen visual representation paradigm BLIP-2 extends into LLM grounding.
- @alayracFlamingo2022 — Flamingo is the closest frozen-backbone multimodal baseline on zero-shot VQA.
- @rameshDALLE2021 — DALL·E is an early large-scale vision-language generative model in the same pre-training lineage.
Further Papers
No vault papers identified as further work yet.