Learning Transferable Visual Models from Natural Language Supervision
Learning Transferable Visual Models from Natural Language Supervision
Problem
Framing
Image classifiers transfer poorly when supervision is a fixed label set. CLIP closes this by training image and text encoders on 400M web pairs, then turning class names into zero-shot classifiers. ImageNet zero-shot reaches 76.2% top-1.
Currently Used Methods
Foundational
- @bengioRepresentationLearning2013 — representation learning frames transfer through reusable features.
- Limitation in context: it does not provide language-grounded supervision.
- @devlinBERT2018 — large-scale language pre-training from raw text.
- Limitation in context: it is unimodal and cannot align images to text.
- @dosovitskiyViT2020 — transformer vision backbone that scales with data.
- Limitation in context: it still depends on closed-set labels.
- "VirTex" — image-to-text pre-training with generative caption prediction.
- Limitation in context: caption generation transfers worse than contrastive alignment.
- "ConVIRT: Contrastive Learning of Visual Representations from Text" — contrastive image-text pre-training in medical imaging.
- Limitation in context: domain scale is far below web supervision.
Proposed Method
Architecture
CLIP learns a shared 512-d space with an image encoder and a text encoder. The image tower is a modified ResNet or ViT. The text tower is a 12-layer transformer over BPE tokens, used at test time to encode prompted class names.
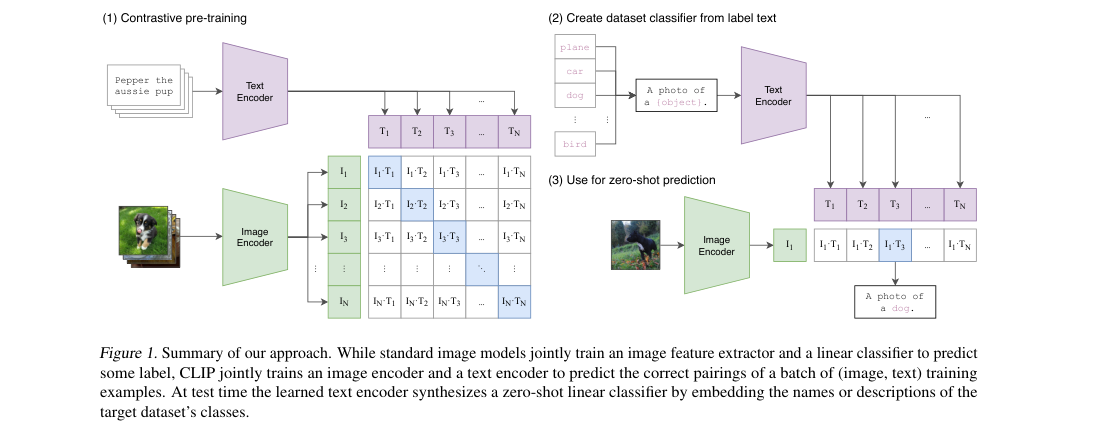
Loss / Objective
The training loss is symmetric cross-entropy over batchwise image-text similarities with learned temperature .
Sampling Rule
Zero-shot classification scores an image against prompted label texts.
Training Procedure
- Dataset: WIT, 400M image-text pairs.
- Query pool: 500,000 text queries.
- Max pairs per query: 20,000.
- Batch size: 32,768.
- Epochs: 32.
- Embedding dimension: 512.
- Vocabulary size: 49,408.
- Models trained: 5 ResNets, 3 ViTs.
- Largest run: 592 V100 GPUs for 18 days.
Evaluation
Datasets
- Pre-training: WIT, 400M image-text pairs.
- Zero-shot transfer: 30+ vision datasets.
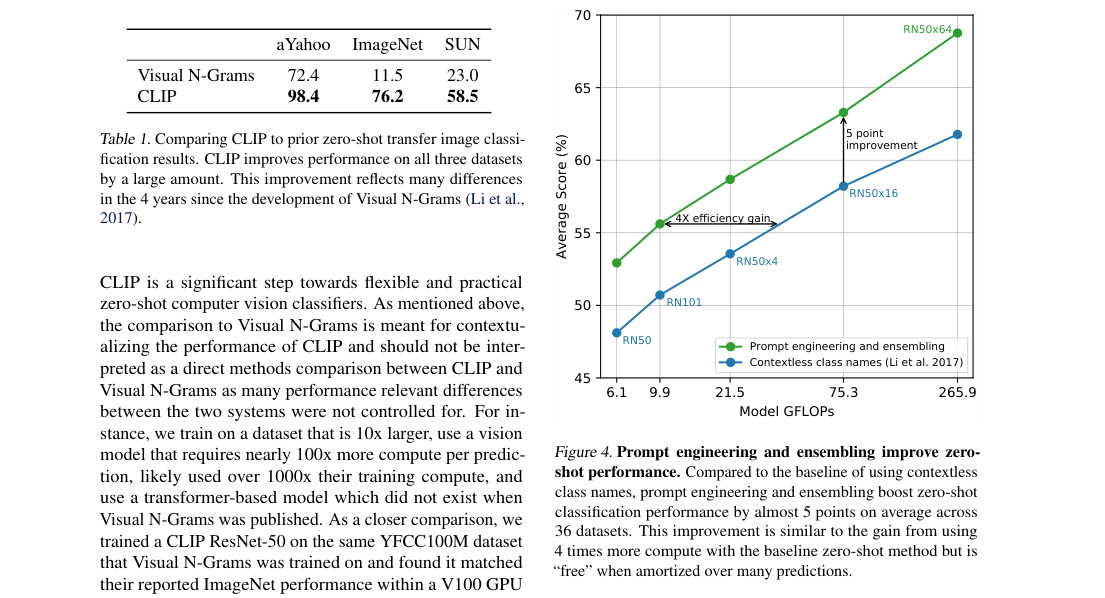
- Classification examples: ImageNet, aYahoo, SUN.
- Robustness: 7 natural distribution-shift datasets.
- Retrieval: Flickr30k, MS-COCO.
Metrics
- Top-1 accuracy.
- Average score across 36 datasets.
- Retrieval recall.
- Robustness gap under shift.
Headline results
- ImageNet zero-shot: 76.2 top-1.
- aYahoo zero-shot: 98.4 top-1.
- SUN zero-shot: 58.5 top-1.
- Average over 36 datasets: prompt engineering and ensembling add almost 5 points.
- Natural distribution shift: robustness gap shrinks by up to 75%.
Ablations
- Contrastive loss vs LM baseline: contrastive transfer is about more compute-efficient.
- Text transformer vs bag-of-words text encoder: bag-of-words transfers about better at equal compute.
- Prompt template choice: "A photo of a {label}." adds 1.3 ImageNet points.
- Prompt ensembling: adds almost 5 average points across 36 datasets.
Method Strengths and Weaknesses
Strengths
- Replaces fixed classifier heads with language-specified classes.
- Reaches 76.2% zero-shot ImageNet top-1.
- Improves robustness under shift by up to 75%.
- Contrastive pre-training beats caption-prediction baselines at matched compute.
Weaknesses
- Training needs 400M pairs and very large compute.
- Zero-shot accuracy is sensitive to prompt wording.
- Class names and templates materially affect results.
- Web data introduces social bias and harmful associations.
Suggestions from the authors
- Scale data, models, and compute beyond the reported runs.
- Improve prompt design and automatic template selection.
- Characterize model biases, harms, and deployment risks.
- Extend natural-language supervision to broader multimodal settings.
Links
Prior Papers
- @bengioRepresentationLearning2013 — frames transfer as reusable representation learning, which CLIP grounds in language supervision.
- @devlinBERT2018 — establishes large-scale language pre-training, mirrored by CLIP on the text side.
- @dosovitskiyViT2020 — provides the ViT image backbone used in CLIP’s model family.
Further Papers
- @rameshDALLE2021 — builds on CLIP-style image-text pre-training for text-conditioned generation.
- @alayracFlamingo2022 — extends large-scale vision-language pre-training toward few-shot multimodal modeling.
- @liBLIP2_2023 — continues modular image-text representation learning with stronger language-model coupling.