An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale
An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale
Problem
Framing
Pure Transformers lacked a competitive image classification recipe because they removed CNN locality bias and overfit at ImageNet scale. The paper closes this gap by treating images as patch sequences and relying on large-scale supervised pre-training. With JFT-300M, ViT-H/14 reaches 88.55% ImageNet top-1.
Currently Used Methods
Foundational
- @vaswaniAttentionAllNeed2017 — standard Transformer encoder with global self-attention.
- Limitation in context: no image tokenization recipe or vision-scale training setup.
- @heDeepResidualLearning2016 — residual CNN baseline for large-scale visual recognition.
- Limitation in context: hard-coded locality remains the dominant competing bias.
- Big Transfer — large-scale supervised ResNet transfer learning.
- Limitation in context: needs more pre-training compute for similar transfer accuracy.
- Noisy Student — semi-supervised EfficientNet scaling for classification.
- Limitation in context: less broad transfer evidence than large-scale ViT.
- DETR — Transformer vision model for detection with object queries.
- Limitation in context: does not validate pure patch Transformers for classification.
Proposed Method
Architecture
ViT splits an image into non-overlapping patches, linearly projects each patch to width , prepends a learned class token, and adds learned 1D position embeddings. A standard Transformer encoder then stacks pre-norm attention and MLP blocks. Main scales are Base , Large , and Huge .
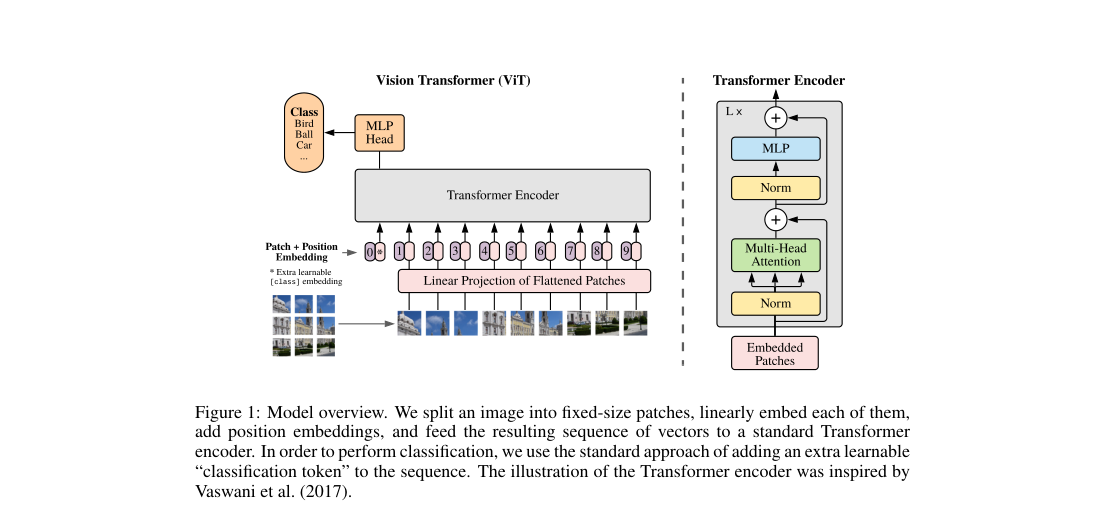
Loss / Objective
The model applies standard classification to the final class token after patch embedding and encoder updates.
Algorithm
Inference runs the encoder on the patch-token sequence and predicts from the final class token.
Training Procedure
- Pre-training batch size: 4096.
- Pre-training warmup: 10k steps.
- Training resolution: 224.
- Fine-tuning batch size: 512.
- Fine-tuning resolution: 384 by default.
- Fine-tuning weight decay: 0.
- Fine-tuning gradient clipping: global norm 1.
- ViT-B/{16,32} on JFT-300M: 7 epochs, base LR , linear decay, weight decay 0.1, dropout 0.0.
- ViT-L/32 on JFT-300M: 7 epochs, base LR , linear decay, weight decay 0.1, dropout 0.0.
Evaluation
Datasets
- Pre-train: ImageNet, ImageNet-21k, JFT-300M.
- Transfer: ImageNet, ImageNet ReaL, CIFAR-10, CIFAR-100, Pets, Flowers.
- Low-data transfer: VTAB-1k with Natural, Specialized, Structured groups.
Metrics
- Top-1 accuracy.
- VTAB average accuracy.
- Linear 5-shot ImageNet top-1.
- Transfer accuracy versus pre-training compute.
Headline results
- ImageNet, JFT-300M ViT-H/14: 88.55% top-1.
- ImageNet ReaL, JFT-300M ViT-H/14: 90.72% top-1.
- ImageNet, JFT-300M ViT-L/16: 87.76% top-1.
- CIFAR-100, ImageNet-pretrained ViT-B/16: 87.13% top-1.
- JFT-300M scaling: ViT reaches the same transfer performance with about less compute than ResNets.
Ablations
- Pre-training dataset size: large ViTs lose on ImageNet-only pre-training, then win with JFT-300M.
- Model scale: larger ViTs benefit more as dataset size grows.
- Architecture type: hybrids help at small compute budgets; the gap disappears at larger scale.
- Self-supervision: masked patch prediction reaches 79.9% ImageNet, still 4 points below supervised pre-training.
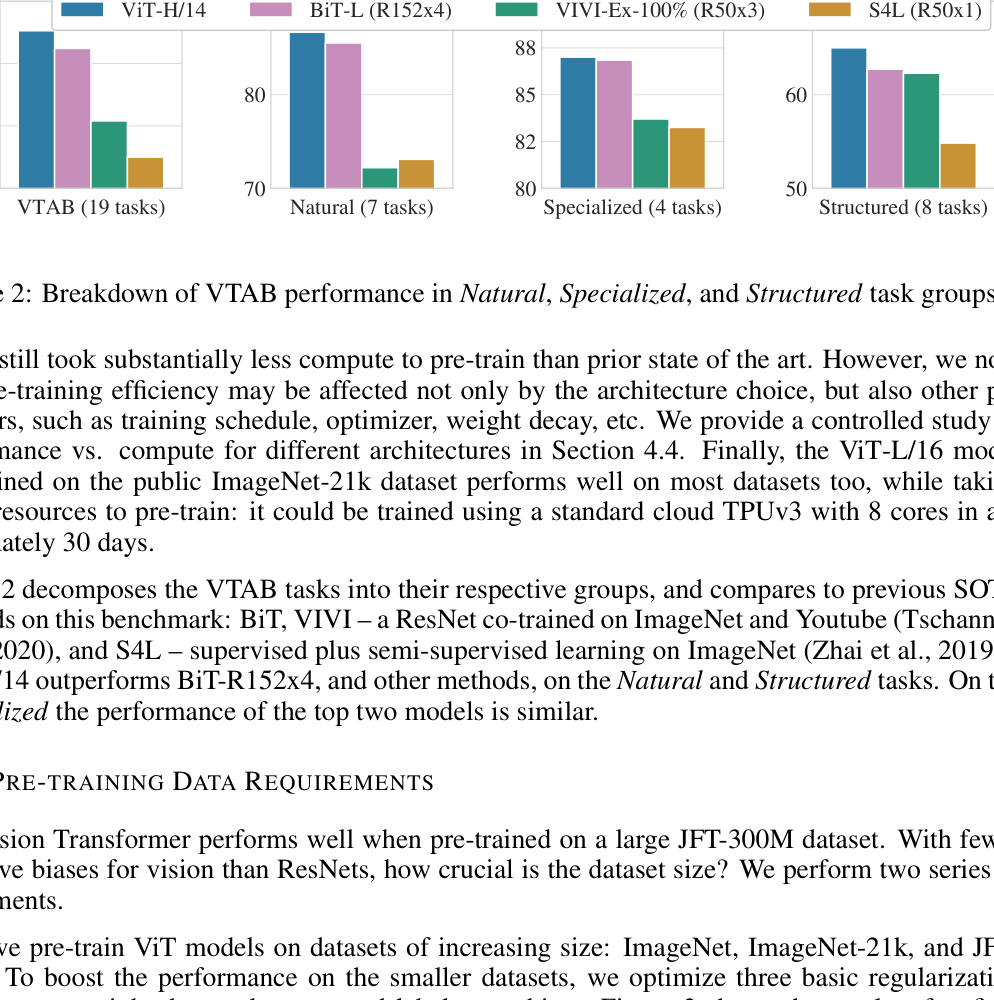
Results figure
The VTAB comparison shows ViT-H/14 leading on the full 19-task average and on Natural and Structured subsets, while Specialized remains close to BiT-L.
Method Strengths and Weaknesses
Strengths
- Patchification is the only bespoke vision bias; the encoder stays almost unchanged.
- JFT-300M pre-training pushes ViT-H/14 to 88.55% ImageNet top-1.
- Scaling study shows better compute-efficiency than ResNets.
- Transfer stays strong across ImageNet, VTAB, and few-shot settings.
Weaknesses
- Large ViTs underperform smaller ones on ImageNet-only pre-training.
- The recipe depends heavily on very large labeled datasets.
- ViT overfits more than ResNets on smaller JFT subsets.
- Masked-patch self-supervision trails supervised pre-training by 4 ImageNet points.
Suggestions from the authors
- Apply ViT to detection and segmentation.
- Analyze few-shot transfer behavior more carefully.
- Improve self-supervised pre-training for patch Transformers.
- Scale model and dataset size further.
Links
Prior Papers
- @vaswaniAttentionAllNeed2017 — supplies the Transformer encoder template that ViT reuses almost unchanged.
- @heDeepResidualLearning2016 — defines the residual CNN baseline family that ViT beats at scale.
- @heMaskRCNN2017 — represents strong vision backbones built on convolutional locality bias.
Further Papers
- @liuSwinTransformer2021 — extends ViT with hierarchical stages and shifted-window attention for dense prediction.
- @radfordCLIP2021 — expands large-scale image Transformer pre-training into multimodal contrastive learning.