Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Problem
Framing
ViT-style backbones keep one token scale and global self-attention, so dense transfer is awkward and image cost stays quadratic. Swin closes this with hierarchical patch merging plus shifted local windows, giving linear image-size complexity and reaching 58.7 box AP, 51.1 mask AP, and 53.5 mIoU.
Currently Used Methods
Foundational
- @dosovitskiyViT2020 — pure Transformer over fixed-size image patches for classification.
- Limitation in context: single-scale features and global attention hinder dense prediction efficiency.
- @heMaskRCNN2017 — strong multi-scale detector-segmenter built on CNN backbones.
- Limitation in context: convolutional backbones lack Transformer-style token interactions.
- @heDeepResidualLearning2016 — deep residual CNN backbone for recognition and transfer.
- Limitation in context: no token attention, so less unified with Transformer pipelines.
- @tanEfficientNet2019 — efficient CNN scaling across depth, width, and resolution.
- Limitation in context: remains convolution-centric, not a hierarchical Transformer backbone.
- DeiT: Training data-efficient image transformers & distillation through attention — makes ViT trainable on ImageNet-1K.
- Limitation in context: still inherits single-resolution ViT structure for dense tasks.
Proposed Method
Architecture
Swin splits the image into non-overlapping patches, linearly embeds them, then applies four stages separated by patch merging. Swin-T uses widths , block counts , and window size . Consecutive blocks alternate W-MSA and SW-MSA.
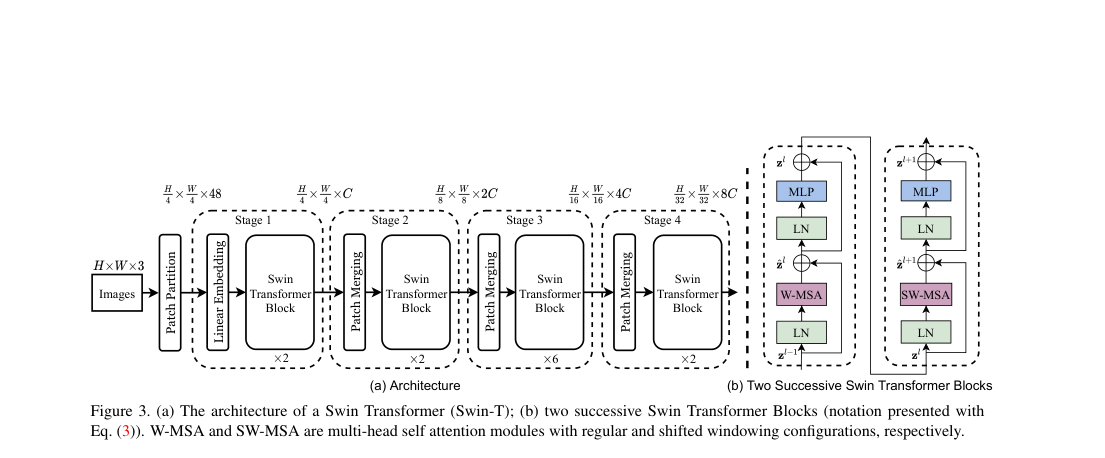
Loss / Objective
For classification, the final-stage feature map is global-average pooled and optimized with cross-entropy.
Algorithm
Each two-block unit alternates regular and shifted window attention with pre-norm residual updates.
Training Procedure
- Patch size:
- Window size:
- ImageNet-1K epochs: 300
- Warm-up: 20 epochs
- Optimizer: AdamW
- Batch size: 1024
- Initial learning rate:
- Weight decay: 0.05
- Gradient clipping max norm: 1
- Stochastic depth: 0.2 / 0.3 / 0.5 for Swin-T / S / B
Evaluation
Datasets
- ImageNet-1K classification
- COCO object detection and instance segmentation
- ADE20K semantic segmentation
- ImageNet-22K pre-training for larger variants
Metrics
- ImageNet: top-1, top-5 accuracy
- COCO: box AP, mask AP
- ADE20K: mIoU
- Efficiency: throughput, FPS, FLOPs
Headline results
- ImageNet-1K classification: 87.3 top-1 accuracy
- COCO test-dev detection: 58.7 box AP, 51.1 mask AP
- ADE20K val segmentation: 53.5 mIoU
- ADE20K, Swin-S vs DeiT-S: 49.3 vs 44.0 mIoU
- Swin-T baseline: 81.3 top-1, 50.5 box AP, 43.7 mask AP, 46.1 mIoU
Ablations
Table 4: Shifted windows and position-bias ablations on ImageNet, COCO, and ADE20K
| method | top-1 | top-5 | APbox | APmask | mIoU |
|---|---|---|---|---|---|
| w/o shifting | 80.2 | 95.1 | 47.7 | 41.5 | 43.3 |
| shifted windows | 81.3 | 95.6 | 50.5 | 43.7 | 46.1 |
| no pos. | 80.1 | 94.9 | 49.2 | 42.6 | 43.8 |
| abs. pos. | 80.5 | 95.2 | 49.0 | 42.4 | 43.2 |
| abs.+rel. pos. | 81.3 | 95.6 | 50.2 | 43.4 | 44.0 |
| rel. pos. w/o app. | 79.3 | 94.7 | 48.2 | 41.9 | 44.1 |
| rel. pos. | 81.3 | 95.6 | 50.5 | 43.7 | 46.1 |
- Shifted vs unshifted windows: +1.1 top-1, +2.8 box AP, +2.2 mask AP, +2.8 mIoU.
- Relative position bias beats none and absolute position encoding across dense tasks.
- Absolute position embedding helps classification slightly, but hurts detection and segmentation.
- Cyclic shifted-window implementation gives 13% / 18% / 18% speedup for T / S / B.
Method Strengths and Weaknesses
Strengths
- Hierarchical stages match FPN and UperNet style dense pipelines.
- Shifted windows recover cross-window interaction with small latency overhead.
- Strong transfer: 58.7 box AP, 51.1 mask AP, 53.5 mIoU.
- Linear image-size complexity fits high-resolution vision better than global attention.
Weaknesses
- One block still attends only within local windows.
- Best headline numbers use ImageNet-22K pre-training for large variants.
- Absolute position embeddings degrade dense prediction performance.
- Gains rely on extra hierarchy machinery beyond vanilla ViT simplicity.
Suggestions from the authors
- Test shifted-window self-attention in natural language processing.
- Push unified modeling of visual and textual signals.
- Extend hierarchical Transformer backbones to more vision tasks.
- Study shifted-window ideas in all-MLP architectures.
Links
Prior Papers
- @dosovitskiyViT2020 — Swin turns ViT into a hierarchical, dense-task-friendly backbone with local shifted attention.
- @heMaskRCNN2017 — Swin is evaluated as a drop-in backbone for COCO detection and instance segmentation.
Further Papers
- @radfordCLIP2021 — overlaps in Transformer-based visual representation learning and scalable vision backbones.
- @alayracFlamingo2022 — later multimodal systems depend on strong visual backbones in Swin's design space.
- @liBLIP2_2023 — vision-language stacks continue the push toward general visual encoders that Swin motivates.