EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Problem
Framing
CNNs had been scaled one dimension at a time, which wastes compute and yields early saturation. EfficientNet closes this gap with compound scaling: jointly scale depth, width, and input resolution from one searched baseline. On ImageNet, EfficientNet-B7 reaches 84.3% top-1 with 66M parameters.
Currently Used Methods
Foundational
- @heDeepResidualLearning2016 — residual connections make very deep CNNs trainable.
- Limitation in context: depth-only scaling gives diminishing accuracy gains.
- @huangDenseNet2017 — dense connectivity improves reuse and gradient flow.
- Limitation in context: no principled rule for joint multi-axis scaling.
- @szegedyGoogLeNet2015 — Inception improves efficiency with hand-crafted factorization.
- Limitation in context: scaling remains manual and architecture-specific.
- MnasNet: Platform-Aware Neural Architecture Search for Mobile — searched mobile backbone with strong efficiency.
- Limitation in context: baseline search alone does not solve large-scale scaling.
- AmoebaNet: Regularized Evolution for Image Classifier Architecture Search — strong NAS classifier family.
- Limitation in context: higher accuracy requires far larger parameter budgets.
Proposed Method
Architecture
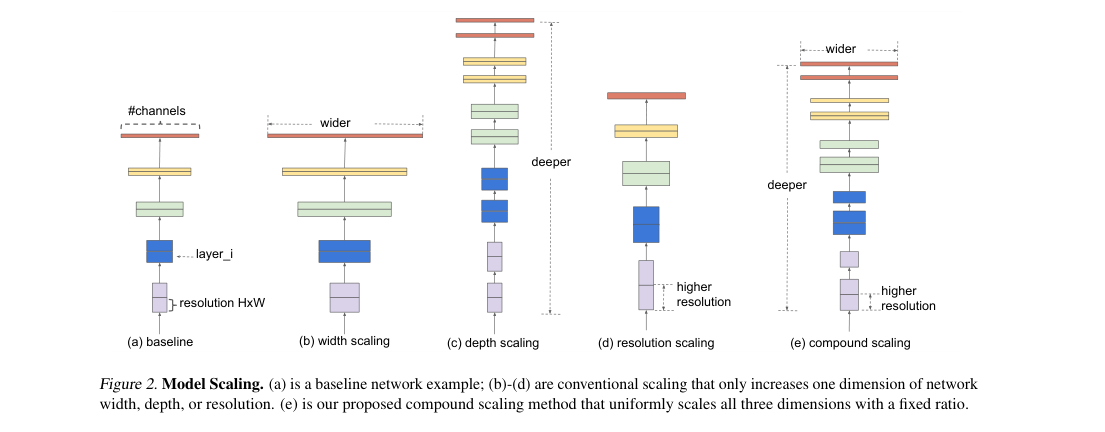
EfficientNet starts from EfficientNet-B0, a NAS-designed MBConv network with squeeze-and-excitation and Swish. It keeps stage structure fixed and scales all stages with one global coefficient .
Loss / Objective
The paper optimizes standard supervised classification loss while changing only the scaling rule.
Scaling Rule / Algorithm
Compound scaling assigns extra compute uniformly across depth, width, and resolution.
Training Procedure
- Optimizer: RMSProp
- Momentum: 0.9
- RMSProp decay: 0.9
- Weight decay:
- Initial learning rate: 0.256
- LR decay: every 2.4 epochs
- Activation: SiLU / Swish
- Model family: B0 through B7
Evaluation
Datasets
- ImageNet
- CIFAR-10
- CIFAR-100
- Flowers
- Stanford Cars
- FGVC Aircraft
- Oxford-IIIT Pets
- Food-101
Metrics
- Top-1 accuracy
- Top-5 accuracy
- Parameter count
- FLOPs
- Single-core CPU latency
- Transfer-learning accuracy
Headline results
- ImageNet, B0: top-1 77.1%, top-5 93.3%, 5.3M params, 0.39B FLOPs.
- ImageNet, B4: top-1 82.9%, top-5 96.4%, 19M params, 4.2B FLOPs.
- ImageNet, B7: top-1 84.3%, top-5 97.0%, 66M params, 37B FLOPs.
- ImageNet, B7 vs GPipe: same 84.3% top-1 with fewer parameters.
- Transfer learning: best on 5 of 8 datasets with fewer parameters on average.
Table 1: ImageNet comparisons at matched accuracy levels show EfficientNet using far fewer parameters and FLOPs.
| Model | Top-1 Acc. | Top-5 Acc. | #Params | Ratio-to-EfficientNet | #FLOPs | Ratio-to-EfficientNet |
|---|---|---|---|---|---|---|
| EfficientNet-B0 | 77.1% | 93.3% | 5.3M | 1x | 0.39B | 1x |
| ResNet-50 | 76.0% | 93.0% | 26M | 4.9x | 4.1B | 11x |
| DenseNet-169 | 76.2% | 93.2% | 14M | 2.6x | 3.5B | 8.9x |
| EfficientNet-B1 | 79.1% | 94.4% | 7.8M | 1x | 0.70B | 1x |
| ResNet-152 | 77.8% | 93.8% | 60M | 7.6x | 11B | 16x |
| DenseNet-264 | 77.9% | 93.9% | 34M | 4.3x | 6.0B | 8.6x |
| Inception-v3 | 78.8% | 94.4% | 24M | 3.0x | 5.7B | 8.1x |
| Xception | 79.0% | 94.5% | 23M | 3.0x | 8.4B | 12x |
| EfficientNet-B2 | 80.1% | 94.9% | 9.2M | 1x | 1.0B | 1x |
| Inception-v4 | 80.0% | 95.0% | 48M | 5.2x | 13B | 13x |
| Inception-resnet-v2 | 80.1% | 95.1% | 56M | 6.1x | 13B | 13x |
| EfficientNet-B3 | 81.6% | 95.7% | 12M | 1x | 1.8B | 1x |
| ResNeXt-101 | 80.9% | 95.6% | 84M | 7.0x | 32B | 18x |
| PolyNet | 81.3% | 95.8% | 92M | 7.7x | 35B | 19x |
| EfficientNet-B4 | 82.9% | 96.4% | 19M | 1x | 4.2B | 1x |
| SENet | 82.7% | 96.2% | 146M | 7.7x | 42B | 10x |
| NASNet-A | 82.7% | 96.2% | 89M | 4.7x | 24B | 5.7x |
| AmoebaNet-A | 82.8% | 96.1% | 87M | 4.6x | 23B | 5.5x |
| PNASNet | 82.9% | 96.2% | 86M | 4.5x | 23B | 6.0x |
| EfficientNet-B5 | 83.6% | 96.7% | 30M | 1x | 9.9B | 1x |
| AmoebaNet-C | 83.5% | 96.5% | 155M | 5.2x | 41B | 4.1x |
| EfficientNet-B6 | 84.0% | 96.8% | 43M | 1x | 19B | 1x |
| EfficientNet-B7 | 84.3% | 97.0% | 66M | 1x | 37B | 1x |
| GPipe | 84.3% | 97.0% | 557M | 8.4x | - | - |
Ablations
- Width scaling: accuracy rises, then saturates near 80%.
- Depth scaling: deeper models help first, then returns taper.
- Resolution scaling: larger inputs help, but gains diminish.
- Compound scaling: best accuracy-efficiency tradeoff at fixed compute.
Method Strengths and Weaknesses
Strengths
- One rule replaces ad hoc depth-only or width-only scaling.
- B7 reaches 84.3% top-1 with 66M parameters.
- Matches GPipe with fewer parameters.
- Wins 5 of 8 transfer datasets with much smaller models.
Weaknesses
- Depends on a strong searched baseline, B0.
- Global ratios limit stage-specific scaling choices.
- Largest model still costs 37B FLOPs.
- Coefficients require search, not full theory.
Suggestions from the authors
- Apply compound scaling to other vision architectures.
- Study scaling under stricter latency and hardware constraints.
- Improve baseline architecture search before scaling.
- Extend the rule to more transfer tasks.
Links
Prior Papers
- @heDeepResidualLearning2016 — establishes deep residual scaling baselines that EfficientNet outperforms at similar accuracy.
- @huangDenseNet2017 — provides compact CNN baselines used in the ImageNet efficiency comparisons.
- @szegedyGoogLeNet2015 — anchors the Inception efficiency line that EfficientNet improves on.
- @heKaimingInit2015 — supports stable optimization in the pre-EfficientNet deep CNN regime.
Further Papers
No vault papers identified as further work yet.