Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
Problem
Framing
Deep rectifier CNNs still fail at depth because Xavier scaling assumes symmetric responses and underestimates variance loss after ReLU. The paper closes this with a learned rectifier, PReLU, and a rectifier-aware initialization rule, then reports 5.71% top-5 single-model error on ImageNet.
Currently Used Methods
Foundational
- @krizhevskyAlexNet2012 — deep ReLU CNNs establish the ImageNet training baseline.
- Limitation in context: deeper rectifier stacks still destabilize under naive scaling.
- @simonyanVGGVeryDeep2014 — very deep small-filter CNNs push accuracy through depth.
- Limitation in context: fixed initialization makes deeper rectifier optimization brittle.
- @ioffeBatchNormalizationAccelerating2015 — normalization stabilizes deep-network optimization.
- Limitation in context: this paper seeks stability without added normalization layers.
- @szegedyGoogLeNet2015 — multi-branch CNNs improve ImageNet accuracy and efficiency.
- Limitation in context: it does not derive rectifier-specific initialization.
- Understanding the difficulty of training deep feedforward neural networks — Xavier initialization preserves linear-layer variance.
- Limitation in context: it ignores ReLU asymmetry in very deep nets.
Proposed Method
Architecture
The paper keeps standard CNN backbones and changes only the activation. PReLU learns a negative slope per channel or per layer, adding negligible parameters relative to convolution weights. The learned slopes are larger in early layers and smaller in deep layers.
Loss / Objective
The modeling change is the learned rectifier itself.
Algorithm
The initialization preserves variance across rectifier layers.
For PReLU with initial slope :
Training Procedure
- Dataset: ImageNet 2012, 1000 classes.
- Input crop: .
- Optimizer: SGD.
- Mini-batch: 128.
- Momentum: 0.9.
- Weight decay: 0.0005.
- Learning rates: , , .
- Schedule: switch when error plateaus.
- Total epochs: about 80.
Evaluation
Datasets
- ImageNet 2012 classification.
- 1000 classes.
- About 1.2M train, 50k validation, 100k test.
Metrics
- Top-1 error.
- Top-5 error.
- Single-crop evaluation.
- Multi-view or multi-scale testing.
Headline results
- ImageNet validation, model C single-model: top-5 5.71%.
- ImageNet test, six-model ensemble: top-5 4.94%.
- ImageNet validation, model A at scale 256: ReLU 8.25 top-5, PReLU 8.08.
- ImageNet validation, model A at scale 384: ReLU 7.26 top-5, PReLU 7.03.
- ImageNet validation, model A multi-scale: ReLU 6.51 top-5, PReLU 6.28.
Table 6: ReLU vs PReLU on ImageNet validation for model A at different test scales.
| model A scale | ReLU top-1 | ReLU top-5 | PReLU top-1 | PReLU top-5 |
|---|---|---|---|---|
| 256 | 26.25 | 8.25 | 25.81 | 8.08 |
| 384 | 24.77 | 7.26 | 24.20 | 7.03 |
| 480 | 25.46 | 7.63 | 24.83 | 7.39 |
| multi-scale | 24.02 | 6.51 | 22.97 | 6.28 |
Ablations
- Activation type: PReLU beats ReLU at every reported test scale.
- Slope granularity: channel-wise and channel-shared PReLU perform similarly on the small model.
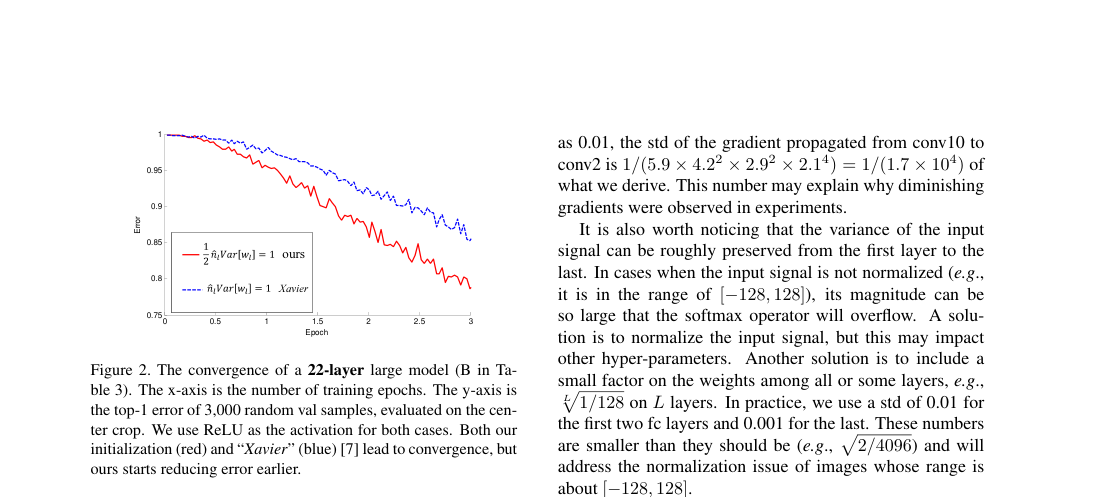
- Initialization: proposed scaling converges for 30-layer rectifier nets where Xavier stalls.
- Test scale : larger scales reduce error for both activations.
Method Strengths and Weaknesses
Strengths
- Derives a closed-form initialization matched to rectifier asymmetry.
- Shows 30-layer convergence where Xavier completely stalls.
- PReLU adds negligible parameters yet improves ImageNet error.
- Reaches 5.71% top-5 single-model error on ImageNet.
Weaknesses
- Single-model PReLU gains over ReLU are modest.
- Best headline test number uses a six-model ensemble.
- Training requires 3–4 weeks on 4–8 GPUs.
- Validation is concentrated on ImageNet classification.
Suggestions from the authors
- Test the initialization in even deeper rectifier networks.
- Study why deep layers learn smaller negative slopes.
- Extend rectifier-aware initialization to other nonlinearities.
- Analyze machine errors against human contextual failures.
Links
Prior Papers
- @krizhevskyAlexNet2012 — establishes the large-scale ReLU CNN baseline that this paper deepens and stabilizes.
- @simonyanVGGVeryDeep2014 — motivates the optimization problem created by pushing rectifier CNN depth upward.
- @szegedyGoogLeNet2015 — serves as a strong contemporary ImageNet comparison point.
- @ioffeBatchNormalizationAccelerating2015 — improves optimization through normalization instead of rectifier-aware initialization.
Further Papers
- @heDeepResidualLearning2016 — extends the same trainability agenda to much deeper CNNs with residual connections.
- @huangDenseNet2017 — continues improving gradient flow and optimization in deep vision networks.
- @tanEfficientNet2019 — revisits CNN scaling after earlier gains from better optimization and architecture design.