Going Deeper with Convolutions
Going Deeper with Convolutions
Problem
Framing
ImageNet CNNs improved by getting deeper and wider, but naive scaling wasted parameters and compute. The paper closes this with Inception: parallel multi-scale branches plus reductions that keep inference near billion multiply-adds. GoogLeNet reaches top-5 error on ILSVRC14.
Currently Used Methods
Foundational
- @krizhevskyAlexNet2012 — large-scale ImageNet CNN baseline with strong classification gains.
- Limitation in context: much larger parameter count for worse top-5 accuracy.
- @simonyanVGGVeryDeep2014 — deeper CNNs from uniform stacks of small convolutions.
- Limitation in context: depth scaling lacks Inception-style multi-branch efficiency.
- @lecunGradientbasedLearningApplied1998 — canonical conv-pool hierarchy for visual recognition.
- Limitation in context: no explicit parallel multi-scale processing inside each stage.
- "Network In Network" — introduces convolutions and local micro-networks.
- Limitation in context: stops short of sparse multi-branch module design.
- @renFasterRCNN2015 — CNN-based region proposal and detection pipeline.
- Limitation in context: backbone efficiency still constrains detection throughput and accuracy.
Proposed Method
Architecture
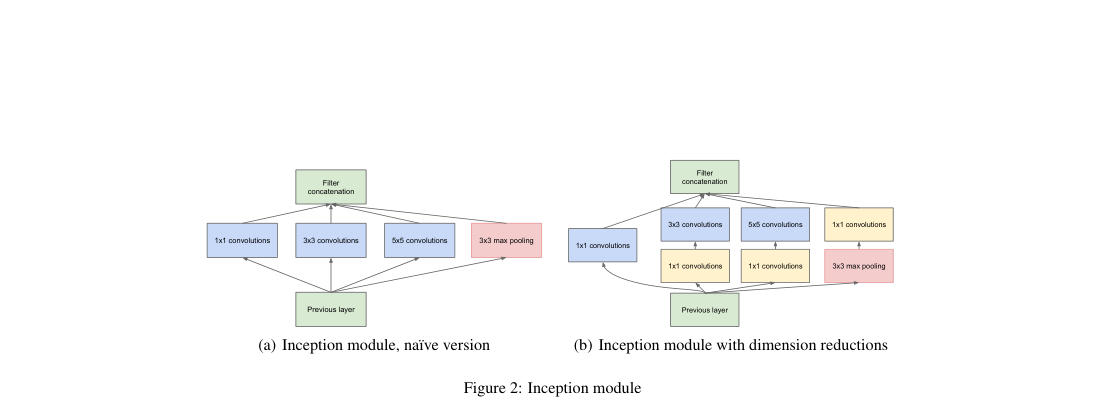
GoogLeNet is a 22-layer CNN built by stacking Inception modules. Each module runs parallel , , , and pooling branches, then concatenates channels; projections reduce cost before the expensive branches. The classifier head replaces large fully connected blocks with global average pooling, and training adds two auxiliary classifiers.
Loss / Objective
Training sums the main softmax loss and two auxiliary softmax losses.
Algorithm
An Inception block applies four branch transforms to and concatenates their outputs.
Training Procedure
- Inference budget: about billion multiply-adds.
- Input size: .
- Auxiliary heads: .
- Auxiliary-loss weight: each.
- Auxiliary-head hidden layer: units.
- Auxiliary-head dropout: dropped outputs.
- Final submission ensemble: models.
- Dense evaluation: crops per image.
Evaluation
Datasets
- ILSVRC 2014 classification: about M train, k validation, k test, classes.
- ILSVRC 2014 detection: classes.
Metrics
- Classification: top-5 error.
- Detection: mean average precision (mAP).
Headline results
- ILSVRC14 classification (single model, single crop): top-5 error.
- ILSVRC14 classification (single model, crops): top-5 error.
- ILSVRC14 classification (-model ensemble): top-5 error.
- ILSVRC14 detection: mAP.
- Parameter efficiency: about fewer parameters than @krizhevskyAlexNet2012.
Table 1: ILSVRC classification challenge leaderboard by top-5 error
| Team | Year | Place | Error (top-5) | Uses external data |
|---|---|---|---|---|
| SuperVision | 2012 | 1st | 16.4% | no |
| SuperVision | 2012 | 1st | 15.3% | Imagenet 22k |
| Clarifai | 2013 | 1st | 11.7% | no |
| Clarifai | 2013 | 1st | 11.2% | Imagenet 22k |
| MSRA | 2014 | 3rd | 7.35% | no |
| VGG | 2014 | 2nd | 7.32% | no |
| GoogLeNet | 2014 | 1st | 6.67% | no |
Ablations
- Crop count: denser evaluation cuts top-5 error from to .
- Ensembling: models cut top-5 error to .
- Auxiliary classifiers: improve optimization in deeper middle layers.
- Wider variant: gives small extra ensemble gains.
Method Strengths and Weaknesses
Strengths
- Wins ILSVRC14 classification with top-5 error.
- Uses about fewer parameters than @krizhevskyAlexNet2012.
- Captures multiple receptive-field scales within one module.
- reductions cut cost before and branches.
Weaknesses
- Best headline number requires a -model ensemble.
- Dense -crop testing is expensive.
- Architecture remains hand-designed and branch-heavy.
- Detection result still depends on proposal-based R-CNN components.
Suggestions from the authors
- Automate Inception topology design instead of hand-crafting modules.
- Test whether the sparse-design principle transfers beyond vision.
- Analyze which architectural choices drive the accuracy gains.
- Reduce memory cost when training deep multi-branch networks.
Links
Prior Papers
- @krizhevskyAlexNet2012 — establishes the ImageNet CNN baseline that GoogLeNet surpasses with far fewer parameters.
- @simonyanVGGVeryDeep2014 — represents the deep uniform-stack design that Inception replaces with multi-branch modules.
Further Papers
- @heKaimingInit2015 — improves optimization for deep rectifier networks, directly relevant to post-GoogLeNet CNN scaling.
- @heDeepResidualLearning2016 — extends the depth-efficiency agenda with residual connections.
- @huangDenseNet2017 — continues efficient deep CNN design through feature reuse and shorter gradient paths.
- @tanEfficientNet2019 — revisits the same accuracy-efficiency tradeoff with principled CNN scaling.