Densely Connected Convolutional Networks
Densely Connected Convolutional Networks
Problem
Framing
Residual nets ease optimization but still fuse features by addition, so earlier representations are not preserved explicitly and parameter reuse stays weak. DenseNet closes this gap by concatenating each layer into all later layers, cutting redundancy and reaching 3.46% error on CIFAR-10+.
Currently Used Methods
Foundational
- @heDeepResidualLearning2016 — identity skips enable very deep CNN optimization.
- Limitation in context: additive fusion does not preserve earlier feature maps.
- @simonyanVGGVeryDeep2014 — plain deep stacks improve accuracy through depth.
- Limitation in context: optimization and parameter cost degrade quickly.
- @szegedyGoogLeNet2015 — multi-branch modules improve compute efficiency.
- Limitation in context: no direct layer-to-layer feature reuse.
- FractalNet: Ultra-Deep Neural Networks without Residuals — parallel fractal paths stabilize deep training.
- Limitation in context: connectivity is indirect and less parameter-efficient.
- Highway Networks — gated shortcuts support deep feed-forward learning.
- Limitation in context: gates add complexity and still mix past features.
Proposed Method
Architecture
A dense block concatenates all previous feature maps into each new layer. CIFAR models use three dense blocks with transition layers of batch normalization, convolution, and average pooling; DenseNet-BC adds bottlenecks and compression .
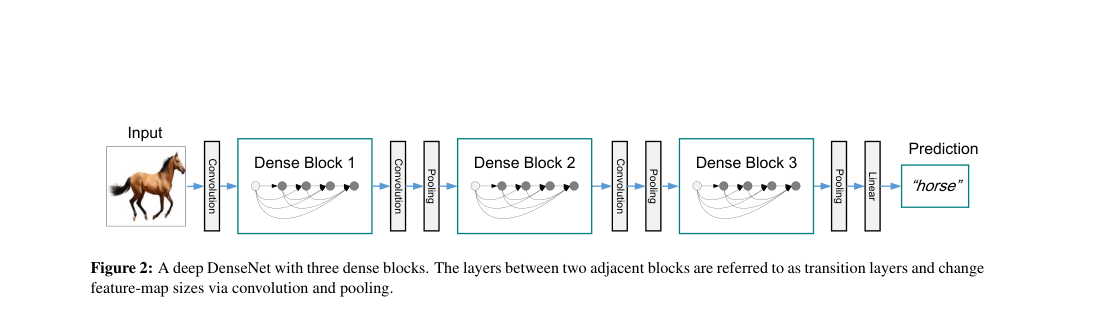
Loss / Objective
The core design is the connectivity rule inside each block.
Algorithm
Channel width grows linearly with growth rate , then transition layers compress it.
Training Procedure
- Optimizer: SGD with Nesterov momentum
- Weight decay:
- CIFAR/SVHN batch size:
- CIFAR/SVHN epochs:
- CIFAR/SVHN learning rate: , divided by at 50% and 75%
- CIFAR/SVHN dropout:
- ImageNet batch size:
- ImageNet epochs:
- ImageNet learning rate: , divided by at epochs and
- Compression factor:
- Bottleneck width: channels before each convolution
Evaluation
Datasets
- CIFAR-10
- CIFAR-10+
- CIFAR-100
- CIFAR-100+
- SVHN
- ImageNet / ILSVRC 2012
Metrics
- Test error rate
- ImageNet top-1 error
- ImageNet top-5 error
- Parameter count
Headline results
- CIFAR-10+ (DenseNet-BC, , ): 3.46% error
- CIFAR-100+ (DenseNet-BC, , ): 17.18% error
- SVHN (DenseNet-BC, , ): 1.59% error
- ImageNet (DenseNet-161): 22.20% top-1, 6.20% top-5
- ImageNet (DenseNet-201): 22.58% top-1, 6.34% top-5
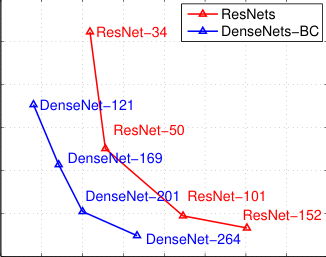
Ablations
- Growth rate : small remains strong because later layers reuse earlier features.
- Bottleneck plus compression: DenseNet-BC improves parameter efficiency with little accuracy loss.
- C10+ parameter sweep: DenseNet-BC needs about one-third the ResNet parameters for similar accuracy.
- Feature reuse analysis: later layers assign non-trivial weight to many earlier maps.
Method Strengths and Weaknesses
Strengths
- Concatenative skips preserve features instead of overwriting them by summation.
- DenseNet-BC matches ResNet accuracy with about one-third the parameters.
- Results hold across CIFAR, SVHN, and ImageNet.
- Small growth rates keep layers narrow without large error increases.
Weaknesses
- Concatenation expands in-block feature width and raises memory traffic.
- Dense connectivity complicates implementation relative to residual stacks.
- Best efficiency depends on bottlenecks and compression design.
- Compute still rises with depth despite parameter savings.
Suggestions from the authors
- Develop more memory-efficient dense connectivity implementations.
- Analyze feature reuse more directly across layers.
- Test dense connectivity beyond image classification.
- Combine dense blocks with other backbone design patterns.
Links
Prior Papers
- @heDeepResidualLearning2016 — DenseNet replaces residual addition with explicit concatenative reuse.
- @heKaimingInit2015 — deep rectifier initialization supports the optimization regime used in these CNNs.
- @simonyanVGGVeryDeep2014 — DenseNet keeps the stacked-convolution template but fixes depth inefficiency.
- @szegedyGoogLeNet2015 — both pursue CNN efficiency, but DenseNet targets reuse through connectivity.
Further Papers
- @tanEfficientNet2019 — extends the CNN efficiency agenda with compound scaling instead of dense connectivity.