High-Resolution Image Synthesis with Latent Diffusion Models
High-Resolution Image Synthesis with Latent Diffusion Models
Problem
Framing
Pixel-space diffusion delivers strong likelihoods, but its cost scales badly with image resolution. The paper shifts diffusion to a perceptually compressed latent space, preserving fidelity while cutting training and sampling cost enough for high-quality synthesis and flexible conditioning.
Currently Used Methods
Foundational
- @DenoisingDiffusionProbabilisticModels2020 — pixel-space diffusion with the standard noise-prediction training objective.
- Limitation in context: reverse diffusion stays expensive at high resolution.
- @dhariwalDiffusionBeatGANs2021 — guided diffusion with strong ImageNet sample quality.
- Limitation in context: still pays full pixel-space training and sampling cost.
- @DenoisingDiffusionImplicitModels2020 — faster non-Markovian diffusion sampling.
- Limitation in context: acceleration alone does not remove pixel-space dimensionality.
- @kingmaVAE2013 — continuous latent compression for cheaper generative modeling.
- Limitation in context: latent models alone did not match diffusion quality.
- @rameshDALLE2021 — two-stage latent generation for text-to-image synthesis.
- Limitation in context: discrete autoregressive priors remain slow and heavy.
Proposed Method
Architecture
LDM splits generation into an autoencoder and a latent diffusion U-Net over . At , typical latent grids are for and for . Conditioning enters by concatenation or cross-attention inside the denoiser.
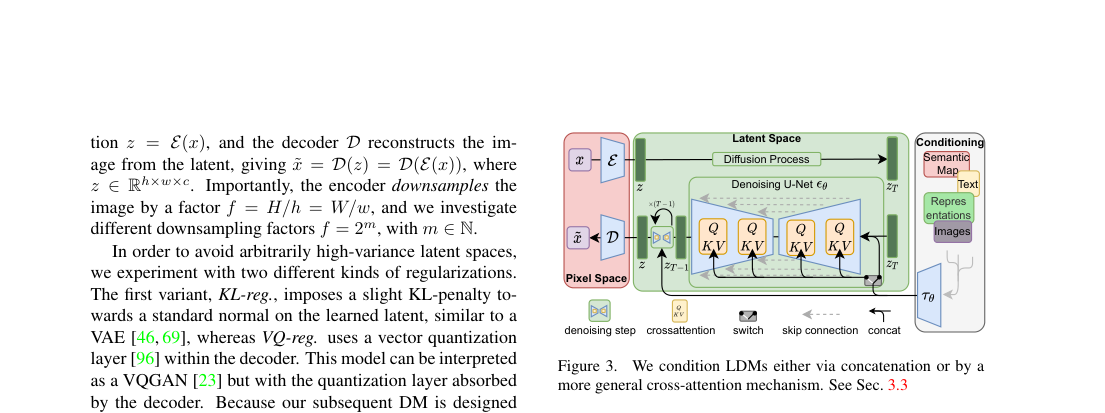
Loss / Objective
The denoiser predicts Gaussian noise in latent space:
Sampling Rule / Algorithm
Sampling runs reverse diffusion on latents, then decodes once at the end:
Training Procedure
- First stage: perceptual + adversarial autoencoder.
- Latent downsampling factors studied: .
- Unconditional models: 500k diffusion training steps.
- Class-conditional ImageNet curves shown up to 2M steps.
- Text-to-image sample figure uses 200 DDIM steps, .
- Text guidance example uses guidance scale .
Evaluation
Datasets
- CelebA-HQ
- FFHQ
- LSUN-Churches
- LSUN-Bedrooms
- ImageNet
- LAION
- COCO
- OpenImages
Metrics
- FID
- IS
- Precision
- Recall
- PSNR
- SSIM
- R-FID
Headline results
- CelebA-HQ unconditional: FID .
- FFHQ unconditional: FID .
- LSUN-Churches unconditional: FID .
- LSUN-Bedrooms unconditional: FID .
- ImageNet class-conditional: competitive with ADM at lower parameter and compute budgets.

Ablations
- Downsampling factor : moderate compression gives the best fidelity-efficiency tradeoff.
- First-stage tokenizer: overly aggressive compression degrades reconstruction and downstream generation.
- Sampling steps: latent models keep strong FID at lower step counts than pixel-space diffusion.
- Conditioning interface: cross-attention extends one backbone across text, layout, class, inpainting, and super-resolution.
Method Strengths and Weaknesses
Strengths
- Cuts diffusion cost by moving denoising to compressed latents.
- One conditioning mechanism covers text, layout, class labels, and image editing.
- Strong unconditional quality: FID on LSUN-Bedrooms.
- Compression ablations give a clear operating regime around to .
Weaknesses
- Quality depends heavily on first-stage autoencoder design.
- High-quality synthesis still needs many DDIM steps.
- Native training resolution in core experiments stays at .
- Reconstruction bottlenecks can discard details before diffusion starts.
Suggestions from the authors
- Improve perceptual compression without losing semantics needed for generation.
- Extend latent diffusion to more vision and multimodal tasks.
- Study better conditioning interfaces than the current cross-attention design.
- Push beyond native training resolution with convolutional or tiled sampling.
Links
Prior Papers
- @DenoisingDiffusionProbabilisticModels2020 — establishes the diffusion objective that LDM transfers from pixels to latents.
- @DenoisingDiffusionImplicitModels2020 — provides the accelerated sampler family used for practical latent diffusion inference.
- @dhariwalDiffusionBeatGANs2021 — supplies the strong pixel-space diffusion baseline LDM seeks to match more efficiently.
- @kingmaVAE2013 — motivates continuous latent compression as the first stage of the model.
- @rameshDALLE2021 — exemplifies two-stage latent generation for text-conditioned image synthesis.
Further Papers
- @ClassifierFreeDiffusionGuidance2022 — becomes a standard guidance method layered onto latent diffusion sampling.
- @alayracFlamingo2022 — shares the paper's emphasis on cross-attention as a scalable multimodal conditioning interface.