Auto-Encoding Variational Bayes
Auto-Encoding Variational Bayes
Problem
Framing
Mean-field VB for directed latent-variable models fails once , , and posterior expectations are all intractable. The paper closes this with a reparameterized lower-bound estimator plus an amortized recognition model, replacing per-datapoint iterative inference with one encoder pass.
Currently Used Methods
Foundational
- "Deep Unsupervised Learning using Nonequilibrium Thermodynamics" — wake-sleep latent-variable training with a learned recognition network.
- Limitation in context: slower convergence and worse variational bounds than AEVB.
- "Estimating or Propagating Gradients Through Stochastic Neurons" — score-function estimators for stochastic computation graphs.
- Limitation in context: gradient variance is too high for practical generic VB.
- Mean-field variational Bayes — analytic lower-bound optimization under simple factorized posteriors.
- Limitation in context: breaks when expectations under nonlinear decoders are intractable.
- Monte Carlo EM with HMC — posterior-sampling-based likelihood learning for latent-variable models.
- Limitation in context: too expensive for online minibatch learning on large datasets.
Proposed Method
Architecture
The model factorizes as with an amortized posterior . In the VAE instantiation, encoder and decoder are single-hidden-layer MLPs; the encoder outputs diagonal-Gaussian and , and the decoder outputs Bernoulli or Gaussian observation parameters.
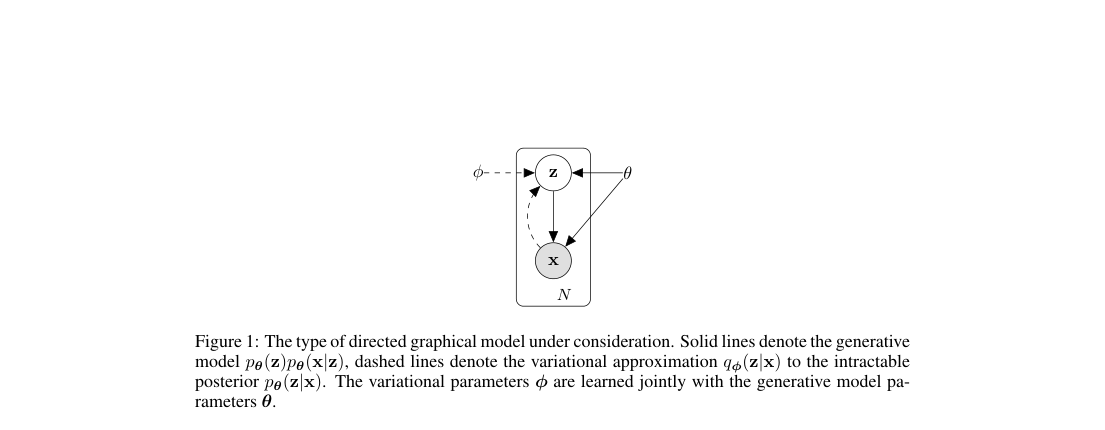
Loss / Objective
The method maximizes the variational lower bound; for the Gaussian VAE with diagonal posterior it uses:
Sampling Rule
Sampling uses the pathwise reparameterization:
Training Procedure
- Minibatch size
- Samples per datapoint
- Optimizer: Adagrad
- Global step size in
- Parameter initialization:
- Weight-decay prior:
- Hidden units: 500 on MNIST, 200 on Frey Face
- Marginal-likelihood runs: 100 hidden units, 3 latent variables
Evaluation
Datasets
- MNIST
- Frey Face
Metrics
- Average variational lower bound per datapoint
- Estimated marginal log-likelihood
Headline results
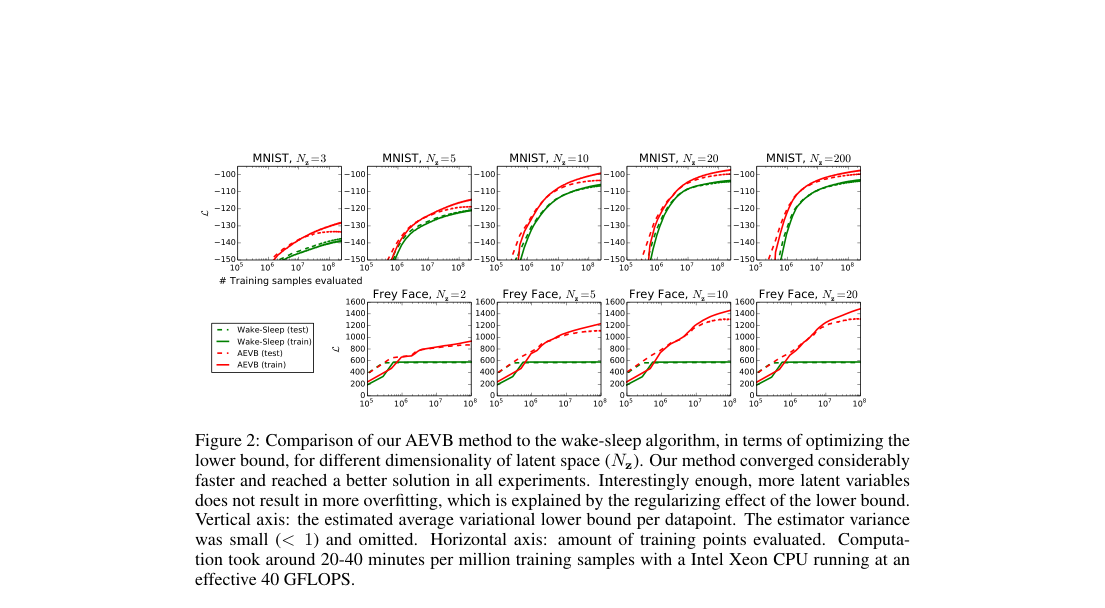
- MNIST : AEVB converges faster and reaches better lower bounds than wake-sleep.
- Frey Face : AEVB converges faster and reaches better lower bounds than wake-sleep.
- MNIST : AEVB improves estimated marginal log-likelihood faster than wake-sleep and MCEM.
- MNIST : MCEM is not efficiently applicable; AEVB remains online.
- Figure 2: estimator variance stays below ; runtime is about - minutes per million samples on CPU.

Ablations
- Latent dimensionality : extra latent variables do not induce visible overfitting.
- Training-set size: AEVB keeps its advantage on both 1k and 50k-example MNIST.
- Objective target: better lower bounds align with better estimated marginal likelihood.
- Algorithm choice: amortized inference beats wake-sleep and avoids MCEM sampling cost.
Method Strengths and Weaknesses
Strengths
- Pathwise gradients avoid the high variance of score-function estimators.
- Amortized inference removes per-example MCMC or inner-loop optimization.
- sampling works in practice with minibatch size .
- Beats wake-sleep on lower bound and marginal likelihood experiments.
Weaknesses
- Core recipe assumes continuous latents with differentiable reparameterization.
- Main posterior family is diagonal Gaussian, which limits expressivity.
- Empirical scope is narrow: MNIST and Frey Face only.
- Marginal-likelihood estimation becomes unreliable at higher latent dimension.
Suggestions from the authors
- Extend the method to variational inference over global parameters.
- Test the appendix algorithm with variational posteriors over model parameters.
- Apply the method to online and non-stationary streaming data.
- Explore richer approximate posteriors beyond diagonal Gaussians.
Links
Prior Papers
No prior vault papers identified yet.
Further Papers
- @DeepUnsupervisedLearningusing2015 — wake-sleep is the direct latent-variable baseline that AEVB outperforms.
- @dinhNVP2017 — extends deep latent-variable density modeling with more expressive invertible transformations.
- @rombachLatentDiffusion2022 — reuses VAE-style encoders and decoders as latent spaces for later generative models.