Density Estimation using Real NVP
Density Estimation using Real NVP
Problem
Framing
Likelihood models still traded off exact density, exact inference, and fast sampling on high-dimensional images. Real NVP closes this with affine coupling maps whose Jacobian is triangular, so density evaluation and inversion stay exact. It reports 3.49 bits/dim on CIFAR-10 and 2.72 on LSUN bedroom.
Currently Used Methods
Foundational
- @kingmaVAE2013 — variational latent-variable modeling with amortized inference.
- Limitation in context: optimizes a bound, not exact likelihood or exact inversion.
- @goodfellowGAN2014 — adversarial generation with sharp samples.
- Limitation in context: no tractable density and no exact latent inference.
- @DeepUnsupervisedLearningusing2015 — autoregressive image density modeling with strong likelihoods.
- Limitation in context: sampling is sequential and slow.
- Improving Variational Inference with Inverse Autoregressive Flow — autoregressive flows for richer variational posteriors.
- Limitation in context: remains tied to variational training, not exact bijective density.
- NICE: Non-linear Independent Components Estimation — coupling layers with tractable inverse and determinant.
- Limitation in context: volume preserving, so it cannot learn local scaling.
Proposed Method
Architecture
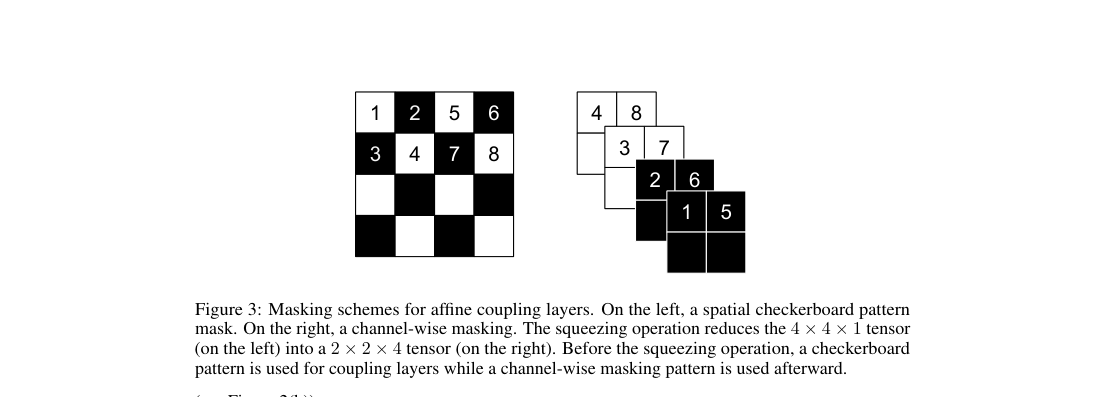
Real NVP stacks affine coupling layers with alternating checkerboard and channel-wise masks. A squeeze operation trades spatial size for channels, and a multi-scale scheme factors out variables across resolutions until a final tensor.
Loss / Objective
Training maximizes exact log-likelihood under change of variables.
Sampling Rule / Algorithm
Each coupling layer is analytically invertible.
Training Procedure
- Prior: isotropic unit Gaussian.
- Input transform: with .
- Data augmentation: horizontal flips for CIFAR-10, CelebA, LSUN.
- Batch size: 64.
- Optimizer: @kingmaAdam2014.
- Regularization: on weight-scale parameters, coefficient .
- images: 4 residual blocks, 32 hidden feature maps.
- images: 2 residual blocks.
- CIFAR-10: 8 residual blocks, 64 feature maps, one downscaling step.
Evaluation
Datasets
- CIFAR-10
- ImageNet
- ImageNet
- LSUN bedroom
- LSUN tower
- LSUN church outdoor
- CelebA
Metrics
- Bits per dimension
- Qualitative sample quality
Headline results
- CIFAR-10: 3.49 bits/dim.
- ImageNet : 4.28 bits/dim.
- ImageNet : 3.98 bits/dim.
- LSUN bedroom: 2.72 bits/dim.
- CelebA: 3.02 bits/dim.
Table 1: Bits/dim results across CIFAR-10, ImageNet, LSUN, and CelebA.
| Dataset | PixelRNN [46] | Real NVP | Conv DRAW [22] | IAF-VAE [34] |
|---|---|---|---|---|
| CIFAR-10 | 3.00 | 3.49 | < 3.59 | < 3.28 |
| Imagenet (32 \times 32) | 3.86 (3.83) | 4.28 (4.26) | < 4.40 (4.35) | |
| Imagenet (64 \times 64) | 3.63 (3.57) | 3.98 (3.75) | < 4.10 (4.04) | |
| LSUN (bedroom) | 2.72 (2.70) | |||
| LSUN (tower) | 2.81 (2.78) | |||
| LSUN (church outdoor) | 3.08 (2.94) | |||
| CelebA | 3.02 (2.97) |
Ablations
- Capacity: limited models generate implausible samples, especially on CelebA.
- Batch normalization: enables deeper coupling stacks and stabilizes scale-parameter training.
- Latent interpolation: traversals stay semantically smooth across faces and scenes.
- Architecture masking: checkerboard masks switch to channel-wise masks after squeezing.
Method Strengths and Weaknesses
Strengths
- Exact likelihood, exact inversion, and exact sampling coexist in one model.
- Affine coupling keeps log-determinants cheap through triangular Jacobians.
- Multi-scale design reaches natural images up to .
- Latent interpolations look semantically organized, not purely local.
Weaknesses
- CIFAR-10 likelihood trails PixelRNN: 3.49 versus 3.00 bits/dim.
- Limited-capacity models produce highly improbable CelebA samples.
- Bijectivity forces latent dimensionality to match input dimensionality.
- Strong results need deep residual coupling networks and normalization.
Suggestions from the authors
- Explore semi-supervised learning with the high-dimensional latent space.
- Build conditional Real NVP models using variables such as class labels.
- Extend the framework to language, video, and audio.
- Learn richer priors over than an isotropic Gaussian.
Links
Prior Papers
- @kingmaVAE2013 — variational latent-variable baseline that Real NVP contrasts with exact likelihood and inversion.
- @goodfellowGAN2014 — sample-quality baseline without tractable density.
- @kingmaAdam2014 — optimizer used in the reported training setup.
Further Papers
- @DenoisingDiffusionProbabilisticModels2020 — later likelihood-based generation revisits the quality-density trade-off with iterative denoising.
- @DenoisingDiffusionImplicitModels2020 — extends the same modern generative-model line while changing the sampling path.
- @songScoreSDE2020 — continuous-time score models target similar density-quality trade-offs.
- @DeepUnsupervisedLearningusing2015 — remains a direct autoregressive comparison point for exact image likelihoods.