Generative Adversarial Networks
Generative Adversarial Networks
Problem
Framing
Generative models still leaned on explicit density estimation or slow Markov chains, both weak fits for sharp image synthesis. GANs replace both with a two-network minimax game that learns direct sampling without a tractable likelihood.
Currently Used Methods
Foundational
- @bengioRepresentationLearning2013 — deep representation learning for hierarchical generative modeling.
- Limitation in context: no adversarial game for direct sample synthesis.
- @kingmaVAE2013 — amortized latent-variable learning with variational likelihood bounds.
- Limitation in context: still depends on explicit probabilistic structure.
- @hintonDeepBeliefNets2006 — multilayer probabilistic generative networks with layerwise training.
- Limitation in context: sampling and inference are less direct.
- A Stochastic Approximation Method — stochastic estimation for latent-variable maximum likelihood.
- Limitation in context: no learned discriminator supplies the training signal.
Proposed Method
Architecture
The method uses two feed-forward networks. The generator maps latent noise to samples, and the discriminator outputs the probability that came from data. Training alternates gradient updates to both players.

Loss / Objective
The core learning rule is a minimax game.
Sampling Rule / Algorithm
Sampling is one generator forward pass from the latent prior.
Training Procedure
- Alternating stochastic gradient updates for and .
- discriminator steps per generator step.
- Minibatch training.
- Practical generator update maximizes .
Evaluation
Datasets
- MNIST
- Toronto Face Database
- CIFAR-10
- ImageNet
Metrics
- Parzen-window log-likelihood estimate
- Visual sample quality
- Latent-space interpolation behavior
Headline results
- MNIST: competitive Parzen-window log-likelihood and coherent digit samples.
- Toronto Face Database: plausible face samples.
- CIFAR-10: recognizable class-conditional samples.
- ImageNet: large-scale qualitative sampling without explicit density estimation.
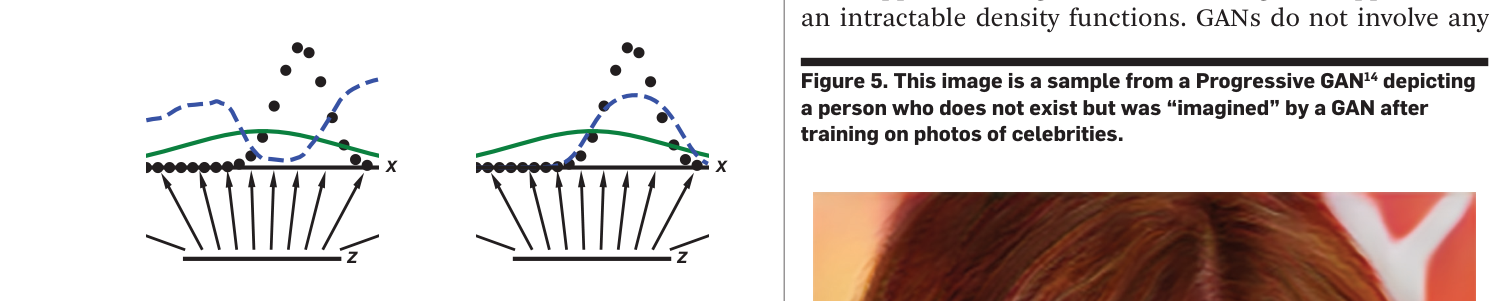
Table 1: The paper's main quantitative comparison is a Parzen-window log-likelihood table on MNIST, but the extracted crop is not the table itself. The visible inspected asset instead shows the 1-D training-dynamics schematic, so no faithful transcription is possible from the available image.
Ablations
- Generator objective: maximizing gives stronger early gradients.
- Training dynamics: discriminator saturation can stall generator learning.
- Game analysis: equilibrium exists when .
- Optimization: convergence speed and spurious equilibria remain open.
Method Strengths and Weaknesses
Strengths
- One forward pass replaces expensive Markov-chain sampling.
- Learned discriminator provides an adaptive loss instead of fixed reconstruction terms.
- The framework avoids explicit density parameterization.
- Demonstrates plausible samples across digits, faces, CIFAR-10, and ImageNet.
Weaknesses
- Training is a saddle-point game with fragile optimization.
- The model gives no tractable likelihood for exact comparison.
- Strong discriminators can leave the generator with weak gradients.
- The original paper reports limited quantitative evidence beyond MNIST.
Suggestions from the authors
- Determine whether spurious Nash equilibria exist.
- Prove whether learning converges to a Nash equilibrium.
- Quantify GAN convergence rates.
- Make adversarial training reliable across applications.
Links
Prior Papers
- @bengioRepresentationLearning2013 — frames the representation-learning agenda that GANs turn into adversarial generation.
Further Papers
- @DeepUnsupervisedLearningusing2015 — extends GANs with convolutional architectures and more stable image synthesis.
- @radfordDCGAN2015 — establishes practical convolutional design rules for GAN training.
- @dinhNVP2017 — offers a contrasting deep generative route with exact likelihood.
- @karrasStyleGAN2019 — pushes GAN fidelity and control far beyond early MLP generators.
- @dhariwalDiffusionBeatGANs2021 — later measures diffusion models against GAN-level image quality.
- @srivastavaDropout2014 — regularization machinery used heavily in deep networks surrounding GAN practice.