Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Problem
Framing
Large neural nets overfit, but explicit test-time averaging over many large nets is too expensive. The paper closes this gap by training random thinned subnetworks and approximating their ensemble with one weight-scaled full network at test time.
Currently Used Methods
Foundational
- @krizhevskyAlexNet2012 — large-scale deep CNN training for visual recognition.
- Limitation in context: improves accuracy, but does not solve overfitting cheaply.
- @goodfellowGAN2014 — adversarial training for sharp generative modeling.
- Limitation in context: not a regularizer for supervised neural nets.
- "Rank, Trace-Norm and Max-Norm" — constrains incoming weight norms during training.
- Limitation in context: regularizes weights, not co-adapting units.
- "ImageNet Classification with Deep Convolutional Neural Networks" — high-capacity convnets with data augmentation and tuning.
- Limitation in context: still needs a generic ensemble-like regularizer.
- "Improving neural networks by preventing co-adaptation of feature detectors" — early masking intuition for hidden units.
- Limitation in context: lacks the full test-time scaling rule and broad evaluation.
Proposed Method
Architecture
Dropout applies to standard multilayer nets, convnets, and RBMs. For each training case, each unit is independently retained with probability and removed otherwise; hidden units use , inputs use larger .
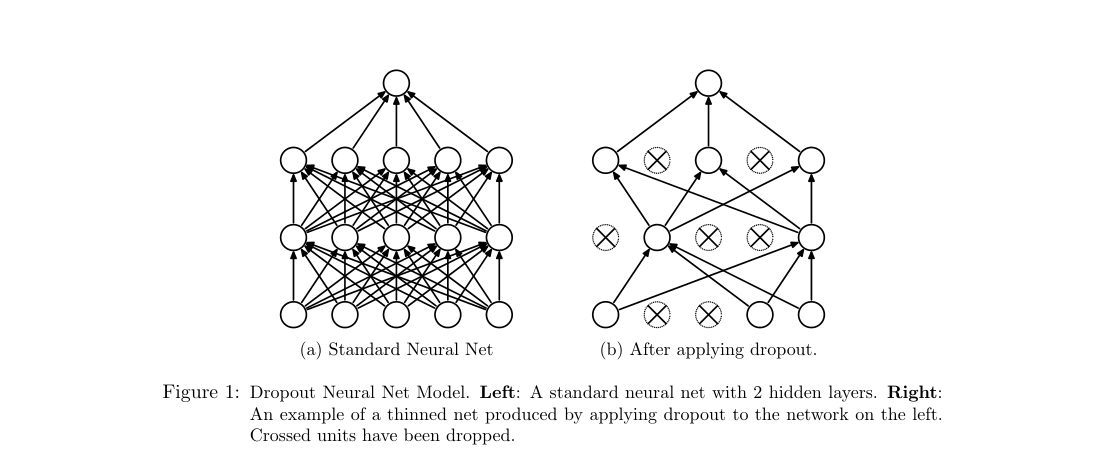
Loss / Objective
Training minimizes the base supervised loss under random Bernoulli masks:
Sampling Rule / Algorithm
Test-time inference uses the full network with outgoing weights scaled by retention probability:
Training Procedure
- Optimizer: stochastic gradient descent with backpropagation.
- Masking: sample a fresh Bernoulli mask for each training case.
- Hidden-layer retention: typically .
- Input-layer retention: closer to than .
- Learning rate: typically -- a standard net.
- Momentum: high momentum.
- Max-norm bound: typical .
Evaluation
Datasets
- MNIST
- SVHN
- CIFAR-10
- CIFAR-100
- ImageNet / ILSVRC-2010, ILSVRC-2012
- TIMIT
- Reuters-RCV1
- splice-junction gene sequences
Metrics
- Classification error rate
- Phone error rate
- Top-1 error
- Top-5 error
Headline results
- MNIST: test error.
- CIFAR-10: error.
- CIFAR-100: error.
- TIMIT core test set: phone error with pretrained dropout nets.
- ILSVRC-2010: top-1, top-5 test error.
Ablations
- Weight scaling vs. explicit averaging: scaling matches ensemble averaging closely.
- Dropout rate on MNIST: remains near-optimal for hidden units.
- Regularizer comparison: dropout plus max-norm beats L2, L1, KL-sparsity, and max-norm alone.
- Bernoulli vs. Gaussian noise: multiplicative Gaussian noise performs similarly.
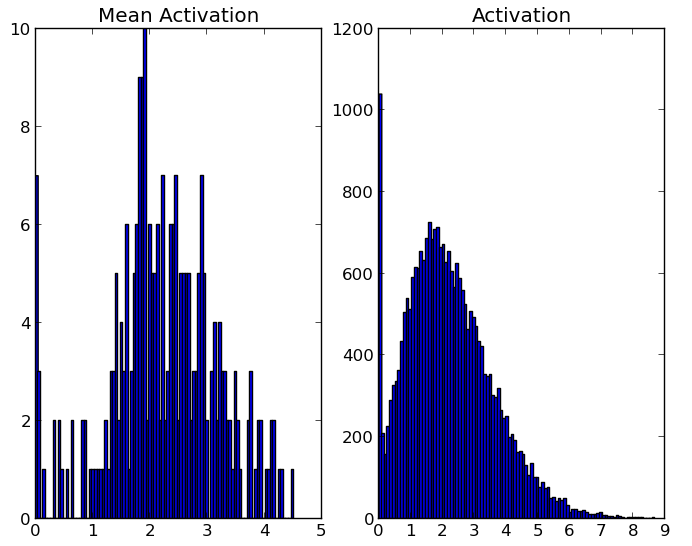
Method Strengths and Weaknesses
Strengths
- One regularizer works across vision, speech, text, and biology benchmarks.
- Test-time cost stays near one model, not an explicit ensemble.
- Weight scaling gives a simple, usable ensemble approximation.
- Dropout plus max-norm beats standard regularizers on MNIST.
Weaknesses
- Adds substantial gradient noise; larger learning rates become necessary.
- Introduces per-layer retention probabilities to tune.
- Test-time averaging is approximate, not exact Bayesian model averaging.
- Reported best architectures remain dataset-specific.
Suggestions from the authors
- Extend dropout analysis to deeper graphical models.
- Study multiplicative noise distributions beyond Bernoulli masks.
- Improve test-time averaging beyond simple weight scaling.
- Explain why dropout reduces co-adaptation and induces sparse features.
Links
Prior Papers
- @krizhevskyAlexNet2012 — high-capacity CNN training defines a regime where dropout becomes useful.
- @goodfellowGAN2014 — another 2014 deep-learning milestone, useful as a neighboring reference point.
Further Papers
- @simonyanVGGVeryDeep2014 — deeper classifier stacks continue to rely on dropout.
- @ioffeBatchNormalizationAccelerating2015 — normalization changes when dropout is needed.
- @heDeepResidualLearning2016 — residual training shifts regularization pressure across depth.