Diffusion Models Beat GANs on Image Synthesis
Diffusion Models Beat GANs on Image Synthesis
Problem
Framing
Diffusion models still trailed BigGAN-class image quality on ImageNet and LSUN. The paper closes that gap with an ablated UNet redesign plus classifier guidance, reaching ImageNet FID 2.97 and guided upsampling FID 3.85 at .
Currently Used Methods
Foundational
- @goodfellowGAN2014 — adversarial training for high-fidelity image synthesis.
- Limitation in context: weaker coverage and unstable training relative to diffusion.
- @DenoisingDiffusionProbabilisticModels2020 — DDPM with UNet -prediction training.
- Limitation in context: ImageNet and LSUN sample quality still trails strong GANs.
- @nicholImprovedDDPM2021 — learned variances and reduced-step diffusion sampling.
- Limitation in context: ImageNet FID still does not beat BigGAN-deep.
- @songScoreSDE2020 — score-based conditioning links diffusion and classifier gradients.
- Limitation in context: this paper targets stronger large-scale image synthesis quality.
- @karrasStyleGAN2019 — strong GAN baseline for photorealistic synthesis.
- Limitation in context: lacks diffusion's likelihood training and coverage advantages.
Proposed Method
Architecture
The model keeps the DDPM UNet family and swaps in empirically stronger blocks. The final setting uses variable width, 2 residual blocks per resolution, attention at , 64 channels per head, BigGAN up/down blocks, and AdaGN for timestep and class conditioning.
Loss / Objective
Training uses the improved-DDPM hybrid objective with learned reverse variances.
Sampling Rule / Algorithm
Classifier guidance shifts the reverse-step mean; for DDIM it modifies noise prediction.
Training Procedure
- Diffusion steps: .
- Batch size: 256 for ImageNet architecture ablations.
- Batch size: 256 for ImageNet guidance experiments.
- Architecture-ablation sampling steps: 250.
- Guidance-study training length: 2M iterations on ImageNet .
- Noise schedule: cosine for ImageNet ; linear for , , .
Evaluation
Datasets
- ImageNet
- ImageNet
- ImageNet
- ImageNet
- LSUN bedroom
- LSUN cat
- LSUN horse
Metrics
- FID
- sFID
- Inception Score
- Precision
- Recall
Headline results
- ImageNet conditional: FID 2.97.
- ImageNet conditional: FID 4.59.
- ImageNet conditional: FID 7.72.
- ImageNet guided upsampling stack: FID 3.94.
- ImageNet guided upsampling stack: FID 3.85.
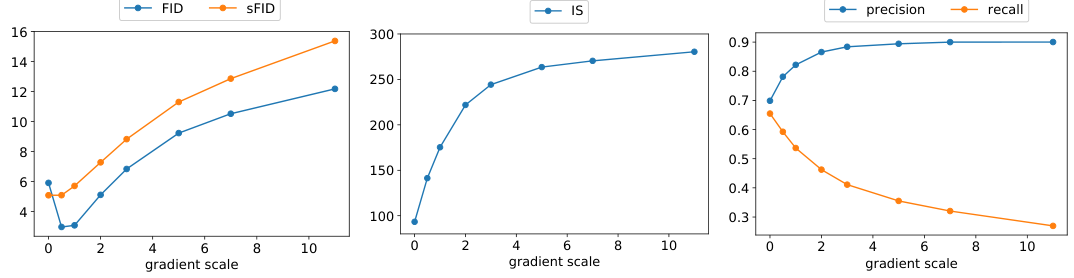
Table 1: Classifier guidance on ImageNet trades diversity for fidelity as gradient scale increases.
| gradient scale | FID | sFID | IS | precision | recall |
|---|---|---|---|---|---|
| 0 | 5.91 | 5.09 | 158.82 | 0.70 | 0.65 |
| 0.5 | 2.97 | 4.69 | 221.57 | 0.78 | 0.61 |
| 1.0 | 3.01 | 5.11 | 253.01 | 0.82 | 0.59 |
| 2.0 | 5.28 | 7.24 | 279.0 | 0.87 | 0.50 |
| 3.0 | 6.94 | 8.94 | 280.48 | 0.89 | 0.45 |
| 5.0 | 9.21 | 11.37 | 291.06 | 0.90 | 0.39 |
| 7.5 | 10.58 | 13.03 | 293.57 | 0.90 | 0.35 |
| 10.0 | 12.14 | 15.36 | 300.28 | 0.90 | 0.28 |
Ablations
- Width versus depth: wider models reach lower FID faster in wall-clock time.
- Attention heads: more heads or fewer channels per head improve FID.
- Attention resolutions: using beats -only attention.
- BigGAN up/down blocks and AdaGN: both improve FID; residual rescaling hurts.
Method Strengths and Weaknesses
Strengths
- Beats BigGAN-class baselines on ImageNet FID across multiple resolutions.
- Guidance gives one scalar knob for fidelity versus diversity.
- Matches BigGAN-deep with as few as 25 forward passes.
- Architecture gains are cumulative across controlled ablations.
Weaknesses
- Guided sampling reduces recall as precision rises.
- Conditional synthesis needs an extra noisy-image classifier.
- Best quality still depends on many denoising steps.
- Final architecture is heavily tuned on ImageNet ablations.
Suggestions from the authors
- Develop better sample-quality metrics beyond FID and IS.
- Improve faster samplers that preserve guided-sampling quality.
- Understand why large guidance scales avoid adversarial failure.
- Leverage unlabeled pretraining before classifier-based specialization.
Links
Prior Papers
- @DenoisingDiffusionImplicitModels2020 — supplies the DDIM sampler used for low-step sampling.
- @DenoisingDiffusionProbabilisticModels2020 — establishes the DDPM framework that this paper scales and improves.
- @goodfellowGAN2014 — defines the adversarial baseline family this paper surpasses on image quality.
- @nicholImprovedDDPM2021 — contributes learned variances and fast-sampling ideas adopted here.
- @songScoreSDE2020 — provides the score-based view behind classifier-guided sampling.
Further Papers
- @ClassifierFreeDiffusionGuidance2022 — removes the external classifier while retaining guidance-based control.
- @DenoisingDiffusionImplicitModels2020 — remains a practical descendant for reduced-step diffusion sampling.
- @rombachLatentDiffusion2022 — pushes diffusion synthesis to latent spaces for cheaper high-resolution generation.