Improved Denoising Diffusion Probabilistic Models
Improved Denoising Diffusion Probabilistic Models
Problem
Framing
DDPMs still pay a steep sampling cost and leave likelihood on the table when reverse variances are fixed. This paper closes both gaps with learned variances, a hybrid -plus-VLB objective, and a cosine noise schedule. CIFAR-10 reaches FID 2.94, and ImageNet 6464 reaches 3.53 bits/dim.
Currently Used Methods
Direct antecedents
- @DenoisingDiffusionProbabilisticModels2020 — DDPM with fixed reverse variances and -prediction training.
- Limitation in context: weak NLL and thousands of sampling steps.
- @DenoisingDiffusionImplicitModels2020 — non-Markovian diffusion sampler for fewer denoising evaluations.
- Limitation in context: speedups are not learned through DDPM variance modeling.
- @DeepUnsupervisedLearningusing2015 — early nonequilibrium diffusion likelihood model.
- Limitation in context: far weaker image quality and scale.
- @songScoreSDE2020 — continuous-time score modeling with strong likelihoods.
- Limitation in context: this paper targets simple discrete ancestral sampling.
Proposed Method
Architecture
The model keeps the DDPM U-Net and changes the reverse-process parameterization. The network predicts the mean through the usual path and learns the variance through an interpolation variable between and .

Loss / Objective
Training uses a hybrid objective that keeps the DDPM denoising loss dominant while adding a small variational term.
Sampling Rule
Sampling remains ancestral, with the learned reverse variance and a cosine cumulative-noise schedule.
Training Procedure
- Diffusion steps: .
- Hybrid-loss weight: .
- Optimizer: Adam.
- Learning rate: .
- EMA decay: .
- Class-conditional ImageNet 6464 sampling steps: 250.
Evaluation
Datasets
- CIFAR-10 unconditional.
- ImageNet 6464 unconditional.
- ImageNet 6464 class-conditional.
- ImageNet 256256 class-conditional.
Metrics
- FID.
- Inception Score.
- NLL in bits/dim.
- Precision.
- Recall.
Headline results
- CIFAR-10 unconditional: FID 2.94.
- ImageNet 6464 unconditional: NLL 3.53 bits/dim.
- ImageNet 6464 class-conditional, small model: FID 19.2, precision 0.66, recall 0.51.
- ImageNet 6464 class-conditional, large model: FID 13.0, precision 0.71, recall 0.54.
- ImageNet 256256 two-stage conditional: 6464 base FID 2.92 before upsampling.
Table 1: Ablating schedule and objective on ImageNet 64 64.
| Iters | T | Schedule | Objective | NLL | FID |
|---|---|---|---|---|---|
| 200K | 1K | linear | 3.99 | 32.5 | |
| 200K | 4K | linear | 3.77 | 31.3 | |
| 200K | 4K | linear | 3.66 | 32.2 | |
| 200K | 4K | cosine | 3.68 | 27.0 | |
| 200K | 4K | cosine | 3.62 | 28.0 | |
| 200K | 4K | cosine | 3.57 | 56.7 | |
| 1.5M | 4K | cosine | 3.57 | 19.2 | |
| 1.5M | 4K | cosine | 3.53 | 40.1 |
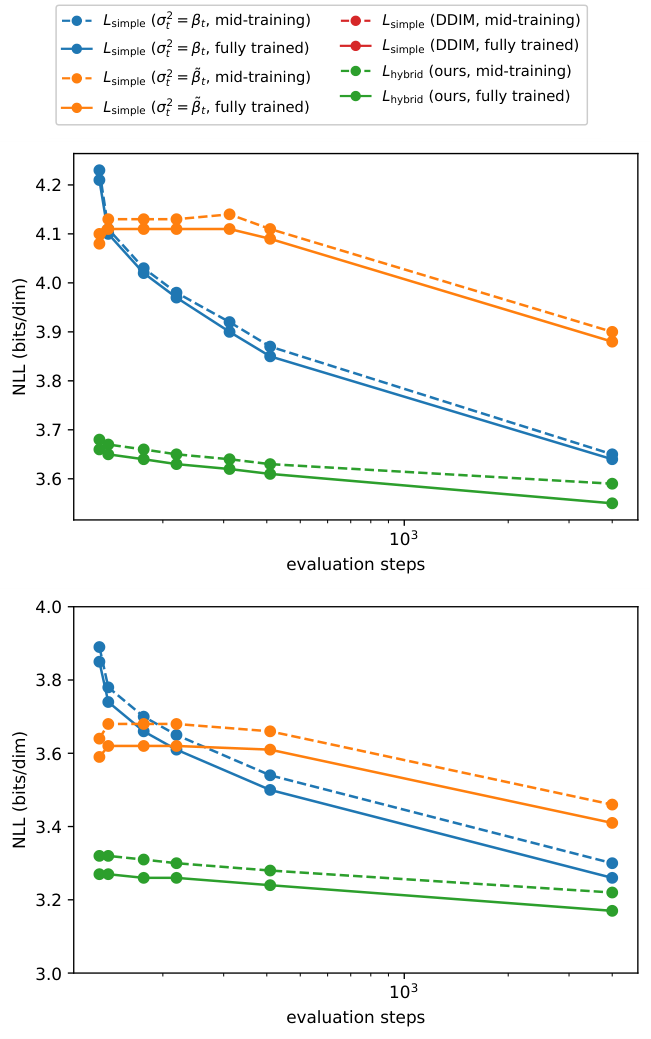
Ablations
- Schedule: cosine beats linear on FID at matched training budget.
- Objective: improves NLL but badly hurts FID.
- Learned variance: enables far fewer reverse steps with modest quality loss.
- Importance-sampled VLB: reduces gradient noise versus direct VLB training.
Method Strengths and Weaknesses
Strengths
- Learned variances make 50-step ancestral sampling viable.
- Cosine scheduling improves FID over linear scheduling.
- Hybrid training improves NLL without collapsing sample quality.
- Precision-recall evaluation shows competitive mode coverage.
Weaknesses
- Best sampler still needs many sequential denoising steps.
- Pure training is noisy and unstable.
- Best NLL and best FID come from different objectives.
- Method still relies on a heavy U-Net backbone.
Suggestions from the authors
- Scale model size and training compute further.
- Design better low-variance likelihood objectives.
- Push sampling to fewer reverse evaluations.
- Extend diffusion upsampling to higher resolutions.
Links
Prior Papers
- @DeepUnsupervisedLearningusing2015 — early diffusion likelihood modeling that this paper strongly improves.
- @DenoisingDiffusionProbabilisticModels2020 — direct baseline for the U-Net, objective, and discrete reverse process.
- @DenoisingDiffusionImplicitModels2020 — complementary fast-sampling diffusion work that frames the speed comparison.
Further Papers
- @dhariwalDiffusionBeatGANs2021 — scales these improved DDPM design choices to much stronger conditional image synthesis.
- @ClassifierFreeDiffusionGuidance2022 — extends the diffusion sampling recipe with guidance for better conditional fidelity.