A Fast Learning Algorithm for Deep Belief Nets
A Fast Learning Algorithm for Deep Belief Nets
Problem
Framing
Deep directed belief nets were hard to train because posterior inference in dense directed layers suffers from explaining away. The paper removes that bottleneck with complementary priors plus greedy layerwise RBM learning, turning deep training into tractable local steps. On permutation-invariant MNIST, it reports 1.25% test error.
Currently Used Methods
Foundational
- @rumelhartLearningRepresentationsBackpropagating1986 — backpropagation for multilayer neural networks.
- Limitation in context: weak optimization and generalization in deep generative nets.
- The Wake-Sleep Algorithm for Unsupervised Neural Networks — Helmholtz-machine learning with recognition and generative weights.
- Limitation in context: mode averaging yields poor recognition weights.
- Variational learning in directed belief nets — approximate posterior inference during likelihood training.
- Limitation in context: deep-layer approximations are poor and joint training scales badly.
- Restricted Boltzmann machines — efficient undirected latent-variable learning.
- Limitation in context: no direct stacking rule for deep directed generative models.
Proposed Method
Architecture
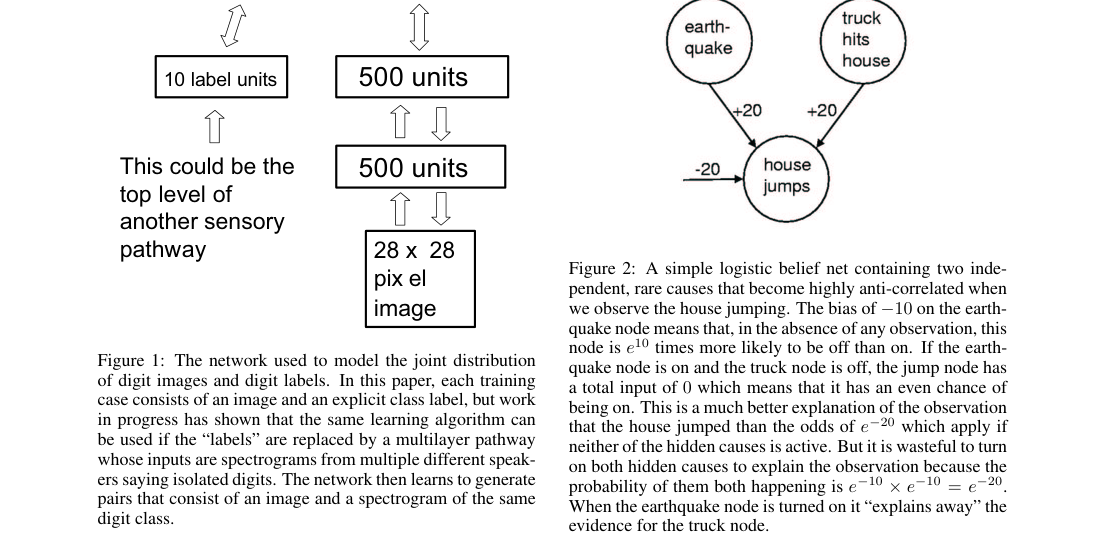
The DBN uses a hybrid stack: a top undirected associative memory and lower directed sigmoid layers. The MNIST model is , with 10 label units coupled at the top.
Loss / Objective
Greedy layer addition improves a variational lower bound on data likelihood.
Sampling Rule / Algorithm
The top RBM uses alternating conditional Bernoulli updates.
Training Procedure
- Architecture: plus 10 labels.
- Parameters: about million weights.
- Initialization: greedy layerwise training, bottom up.
- Top layer: alternating Gibbs sampling in the associative memory.
- Fine-tuning: contrastive up-down wake-sleep variant.
Evaluation
Datasets
- MNIST handwritten digits.
- 60,000 training images.
- 10,000 test images.
Metrics
- Test error % on digit classification.
Headline results
- MNIST permutation-invariant: 1.25% test error.
- MNIST permutation-invariant, SVM degree-9 polynomial: 1.4%.
- MNIST permutation-invariant, backprop : 1.51%.
- MNIST permutation-invariant, backprop : 1.53%.
- MNIST permutation-invariant, nearest neighbor with all 60,000 examples and : 2.8%.
Table 1: MNIST test-error comparison across permutation-invariant and geometry-aware baselines
| Version of MNIST task | Learning algorithm | Test error % |
|---|---|---|
| permutation-invariant | Our generative model 784\rightarrow500\rightarrow500\leftrightarrow2000\leftrightarrow10 | 1.25 |
| permutation-invariant | Support Vector Machine degree 9 polynomial kernel | 1.4 |
| permutation-invariant | Backprop 784\rightarrow500\rightarrow300\rightarrow10 cross-entropy & weight-decay | 1.51 |
| permutation-invariant | Backprop 784\rightarrow800\rightarrow10 cross-entropy & early stopping | 1.53 |
| permutation-invariant | Backprop 784\rightarrow500\rightarrow150\rightarrow10 squared error & on-line updates | 2.95 |
| permutation-invariant | Nearest Neighbor All 60,000 examples & L3 norm | 2.8 |
| permutation-invariant | Nearest Neighbor All 60,000 examples & L2 norm | 3.1 |
| permutation-invariant | Nearest Neighbor 20,000 examples & L3 norm | 4.0 |
| permutation-invariant | Nearest Neighbor 20,000 examples & L2 norm | 4.4 |
| unpermuted images extra data from elastic deformations | Backprop cross-entropy & early-stopping convolutional neural net | 0.4 |
| unpermuted deskewed images, extra data from 2 pixel transl. | Virtual SVM degree 9 polynomial kernel | 0.56 |
| unpermuted images | Shape-context features hand-coded matching | 0.63 |
| unpermuted images extra data from affine transformations | Backprop in LeNet5 convolutional neural net | 0.8 |
| Unpermuted images | Backprop in LeNet5 convolutional neural net | 0.95 |
Ablations
- Permutation invariance: the DBN stays competitive without geometric priors.
- Training strategy: generative pretraining beats plain backprop baselines.
- Neighbor count and norm: nearest-neighbor error rises with fewer samples and distance.
- Geometry-aware models: convolutional systems still win on unpermuted images.
Method Strengths and Weaknesses
Strengths
- Replaces hard joint training with tractable greedy RBM fitting.
- Gives a concrete mechanism to cancel explaining away.
- Beats permutation-invariant backprop and SVM baselines on MNIST.
- Keeps a full generative model with label-conditioned sampling.
Weaknesses
- Final accuracy still trails convolutional models with image priors.
- Sampling depends on Gibbs updates in the top associative memory.
- Fine-tuning still needs separate recognition and generative passes.
- Empirical scope is narrow and dominated by MNIST.
Suggestions from the authors
- Replace labels with another sensory pathway such as speech spectrograms.
- Extend complementary-prior ideas beyond stochastic binary units.
- Back-fit earlier layers after greedy construction.
- Probe the model by unconstrained generative runs.
Links
Prior Papers
- @rumelhartLearningRepresentationsBackpropagating1986 — baseline multilayer learning that DBN pretraining improves on for deep models.
Further Papers
- @bengioRepresentationLearning2013 — places DBNs as a central step in deep representation learning.
- @DeepUnsupervisedLearningusing2015 — revisits unsupervised layerwise pretraining after the DBN era.