Adam: A Method for Stochastic Optimization
Adam: A Method for Stochastic Optimization
Problem
Framing
Stochastic optimizers split between sparse-gradient adaptivity and robustness to non-stationary objectives. Adam closes that gap with bias-corrected first and second moments, giving low-memory parameter-wise steps that work across convex and deep non-convex training.
Currently Used Methods
Foundational
- "Adaptive Subgradient Methods for Online Learning and Stochastic Optimization" — per-parameter steps from accumulated squared gradients.
- Limitation in context: past gradients accumulate forever, so updates decay too aggressively.
- "Lecture 6e rmsprop: Divide the gradient by a running average of its recent magnitude" — exponential second-moment normalization for stochastic training.
- Limitation in context: no bias correction, so early steps can be badly distorted.
- "On the importance of initialization and momentum in deep learning" — Nesterov momentum accelerates first-order optimization.
- Limitation in context: one global learning rate handles sparse coordinates poorly.
- "An Efficient Natural Gradient Descent Method" — diagonal natural-gradient preconditioning with online curvature estimates.
- Limitation in context: less practical and less conservative than moment-based scaling.
- "Sum-of-Functions Optimizer" — minibatch quasi-Newton optimization for neural networks.
- Limitation in context: heavier iterations and less attractive memory-cost tradeoffs.
Proposed Method
Architecture
Adam is an optimizer, not a network architecture. It stores two state tensors per parameter: first moment and second moment , then applies a bias-corrected normalized step.
Loss / Objective
The method minimizes a stochastic objective through moment-tracked first-order updates.
Algorithm
Bias correction removes the zero-initialization shrinkage before the parameter update.
Training Procedure
- Default
- Default
- Default
- Default
- Logistic regression minibatch size:
- Multilayer network hidden width:
- Multilayer network minibatch size:
- CNN architecture: c64-c64-c128-1000
- CNN training horizon: epochs
Evaluation
Datasets
- MNIST logistic regression
- IMDB bag-of-words logistic regression
- MNIST multilayer neural networks
- CIFAR-10 convolutional neural networks
- Variational auto-encoder bias-correction study
Metrics
- Training negative log-likelihood
- Training cost
- Iterations over entire dataset
- Wall-clock convergence
- Loss after fixed training epochs
Headline results
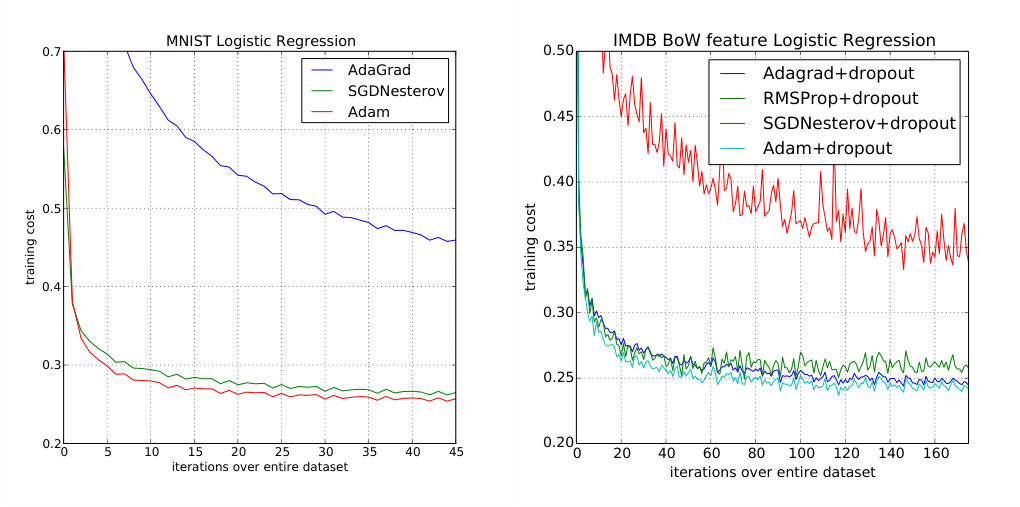
- MNIST logistic regression: Adam reaches lower training cost than AdaGrad and SGDNesterov.
- IMDB BoW logistic regression: Adam matches AdaGrad and RMSProp, and beats SGDNesterov.
- MNIST multilayer networks: Adam outperforms first-order baselines and SFO in progress and time.
- CIFAR-10 CNN: Adam and SGDNesterov converge much faster than AdaGrad over epochs.
- VAE bias study: bias correction prevents very large updates when is near .
Ablations
- Bias correction on/off: removing correction destabilizes training, especially for large .
- Objective class: Adam works on both convex logistic regression and non-convex neural nets.
- Sparse features: IMDB BoW preserves AdaGrad-like gains without sacrificing momentum.
- Training horizon: on CIFAR-10, Adam starts fast and stays competitive through long runs.
Method Strengths and Weaknesses
Strengths
- Combines momentum and adaptive scaling in one parameter-wise update.
- Bias correction fixes severe early-step shrinkage from zero-initialized moments.
- Matches strong sparse-feature baselines on IMDB bag-of-words logistic regression.
- Beats first-order baselines on MNIST multilayer networks and competitive CNN training.
Weaknesses
- Theory targets online convex optimization, not deep non-convex convergence.
- Evaluation emphasizes training curves more than final test accuracy.
- CIFAR-10 results show SGDNesterov remains highly competitive late in training.
- Method still exposes four coupled hyperparameters to tune.
Suggestions from the authors
- Extend Adam to alternative normalization, including the AdaMax limit.
- Tighten convergence analysis beyond the presented online convex setting.
- Test the method on larger datasets and higher-dimensional parameter spaces.
- Analyze moment bias and dynamics further in non-convex objectives.
Links
Prior Papers
No prior vault papers identified yet.
Further Papers
- @dinhNVP2017 — deep generative modeling paper from the Adam era that plausibly relies on Adam-style adaptive optimization.
- @loshchilovAdamW2019 — revisits Adam directly and decouples weight decay from adaptive gradient updates.