Decoupled Weight Decay Regularization
Decoupled Weight Decay Regularization
Problem
Framing
Adam used coupled regularization, which is not equivalent to weight decay under adaptive preconditioning. The paper fixes this by decoupling parameter shrinkage from the gradient step, yielding AdamW and SGDW with better tuning behavior and about 15% relative test-error gains on image classification.
Currently Used Methods
Foundational
- @kingmaAdam2014 — Adam with adaptive first- and second-moment preconditioning.
- Limitation in context: coupled shrinkage is distorted by coordinate-wise scaling.
- SGDR: Stochastic Gradient Descent with Warm Restarts — cosine schedules and restart-based anytime improvement.
- Limitation in context: does not repair Adam's regularization mismatch.
- Shake-Shake regularization — strong residual-network baseline for image classification.
- Limitation in context: orthogonal to optimizer-side decay behavior.
- Weight decay — multiplicative parameter shrinkage in SGD updates.
- Limitation in context: standard Adam implementations replace it with non-equivalent coupling.
Proposed Method
Architecture
The contribution is optimizer-side. AdamW keeps Adam's moment estimates and applies decay as a separate parameter shrinkage term. Experiments use Shake-Shake ResNets, mainly 26 2x64d and 26 2x96d.
Loss / Objective
The key change is to separate loss gradients from decay.
Algorithm
AdamW preserves Adam's adaptive step and decouples shrinkage from the gradient term.
\\begin{aligned} \\mathbf{m}_t &= \\beta_1 \\mathbf{m}_{t-1} + (1-\\beta_1) \\, \\nabla f_t(\\boldsymbol{\\theta}_{t-1}), \\\\ \\mathbf{v}_t &= \\beta_2 \\mathbf{v}_{t-1} + (1-\\beta_2) \\, \\nabla f_t(\\boldsymbol{\\theta}_{t-1})^{\\odot 2}, \\\\ \\hat{\\mathbf{m}}_t &= \\mathbf{m}_t / (1-\\beta_1^t), \\qquad \\hat{\\mathbf{v}}_t = \\mathbf{v}_t / (1-\\beta_2^t), \\\\ \\boldsymbol{\\theta}_t &= \\boldsymbol{\\theta}_{t-1} - \\alpha_t \\left( \\frac{\\hat{\\mathbf{m}}_t}{\\sqrt{\\hat{\\mathbf{v}}_t}+\\epsilon} + \\lambda \\, \\boldsymbol{\\theta}_{t-1} \\right) \\end{aligned}Training Procedure
- Adam defaults: , , ,
- Batch size: 128
- Main sweep: 100 epochs
- Long-run comparison: 1800 epochs
- Step-drop epochs: 30, 60, 80
- Schedules: fixed, step-drop, cosine annealing
- Restarted variants: SGDW, AdamW, SGDWR, AdamWR
Evaluation
Datasets
- CIFAR-10
- ImageNet32x32
Metrics
- CIFAR-10: Top-1 test error
- ImageNet32x32: Top-5 test error
Headline results
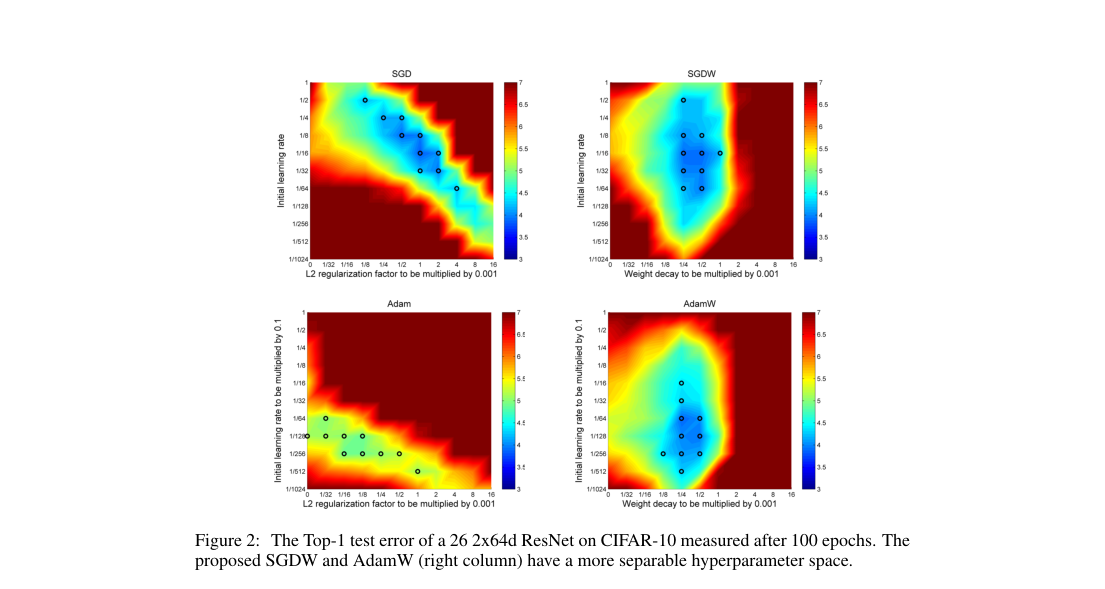
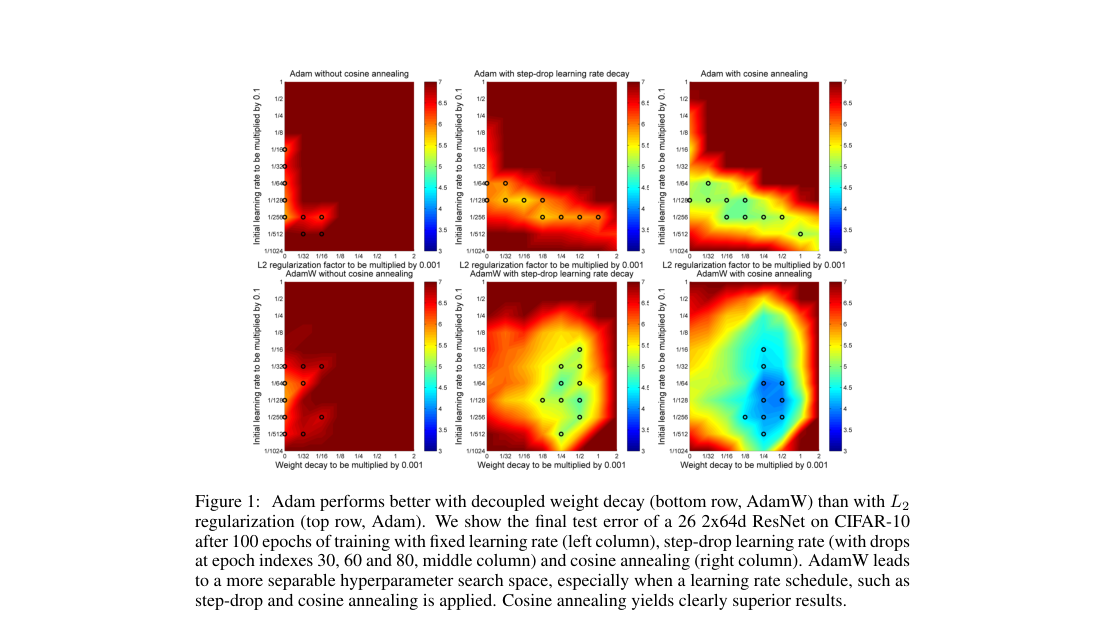
- CIFAR-10, 100 epochs: AdamW beats Adam across fixed, step-drop, and cosine schedules.
- CIFAR-10, 100 epochs: AdamW shows a broader, more separable learning-rate/decay basin.
- CIFAR-10 and ImageNet32x32: decoupled decay gives about 15% relative test-error improvement over Adam.
- CIFAR-10 and ImageNet32x32: AdamWR improves anytime performance by up to .
- CIFAR-10, 1800 epochs: AdamW improves both training loss and test error over tuned Adam.
Ablations
- Learning-rate schedule: cosine annealing gives the lowest errors.
- Regularization form: decoupled decay makes tuning less entangled.
- Training budget: optimal raw decay changes with epoch count.
- Warm restarts: early performance improves sharply for AdamWR and SGDWR.
Method Strengths and Weaknesses
Strengths
- One-line optimizer change fixes a real mismatch in Adam regularization.
- Heatmaps show wider good hyperparameter regions for AdamW.
- Reports about 15% relative error reduction over Adam.
- Combines cleanly with cosine schedules and warm restarts.
Weaknesses
- Evidence is concentrated on image classification.
- Main comparisons target Adam, not later adaptive optimizers.
- Best raw decay still shifts with training budget.
- The method improves optimization, not model expressivity.
Suggestions from the authors
- Normalize weight decay across different training budgets.
- Study scheduled global learning-rate multipliers for Adam-style methods.
- Extend decoupled decay with warm restarts for better anytime behavior.
- Test decoupled decay on broader adaptive optimizers and workloads.
Links
Prior Papers
- @kingmaAdam2014 — AdamW modifies Adam by separating weight decay from the adaptive gradient update.
Further Papers
No vault papers identified as further work yet.