Neural Machine Translation by Jointly Learning to Align and Translate
Neural Machine Translation by Jointly Learning to Align and Translate
Problem
Framing
Encoder–decoder NMT compressed the full source sentence into one fixed-length vector, and translation quality collapsed on long inputs. This paper replaces that bottleneck with soft alignment over encoder annotations at each decoding step. On WMT’14 English→French, the attentive model reaches 28.45 BLEU.
Currently Used Methods
Direct antecedents
- @sutskeverSeq2Seq2014 — seq2seq encoder–decoder for end-to-end translation.
- Limitation in context: fixed-length source vector bottlenecks long sentences.
- @choGRU2014 — gated RNN encoder–decoder for neural translation.
- Limitation in context: decoding still relies on one global context vector.
- Recurrent Continuous Translation Models — early neural translation without phrase tables.
- Limitation in context: no learned soft alignment over source positions.
- A Neural Network for Machine Translation, at Production Scale — large-scale production neural MT.
- Limitation in context: the encoder bottleneck remains for long inputs.
Proposed Method
Architecture
A bidirectional encoder produces annotations . The decoder updates from and a step-specific context , then predicts . The architecture figure shows decoder states attending over all source annotations with weights .

Loss / Objective
Training maximizes the conditional log-likelihood of the target sentence given the source sentence.
Sampling Rule / Algorithm
At each decoding step, the model recomputes alignment weights and the context vector before predicting the next token.
Training Procedure
- Optimizer: Adadelta with , .
- Gradient clipping: .
- Minibatch size: 80 sentences.
- Vocabulary: 30,000 most frequent words per language.
- Training variants: maximum sentence length 30 and 50.
- Hidden size: 1000.
- Embedding size: 620.
- Maxout hidden size: 500.
- Alignment hidden size: 1000.
Evaluation
Datasets
- WMT’14 English→French parallel data.
- Training corpus reduced to 348M words after selection.
- Development: news-test-2012 and news-test-2013.
- Test: news-test-2014, 3003 sentences.
- Baselines: RNNencdec and Moses.
Metrics
- BLEU on the full test set.
- BLEU on sentences without unknown words.
- BLEU versus source-sentence length.
Headline results
- English→French, RNNencdec-30: BLEU 13.93, no-UNK BLEU 24.19.
- English→French, RNNsearch-30: BLEU 21.50, no-UNK BLEU 31.44.
- English→French, RNNencdec-50: BLEU 17.82, no-UNK BLEU 26.71.
- English→French, RNNsearch-50: BLEU 28.45, no-UNK BLEU 33.08.
- English→French, Moses: BLEU 30.64, no-UNK BLEU 33.30.
Table 1: BLEU scores on the WMT’14 English→French test set.
| Model | All | No UNK |
|---|---|---|
| RNNencdec-30 | 13.93 | 24.19 |
| RNNsearch-30 | 21.50 | 31.44 |
| RNNencdec-50 | 17.82 | 26.71 |
| RNNsearch-50 | 28.45 | 33.08 |
| Moses | 30.64 | 33.30 |
Ablations
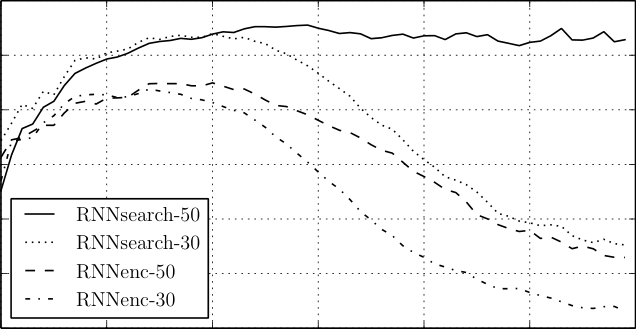
- Maximum training length 30 → 50: both models improve, and attention gains more.
- Source length sweep: RNNencdec drops sharply on long sentences.
- Attention versus no attention: per-step context preserves long-sentence quality.
- Unknown-word filtering: RNNsearch nearly matches Moses on no-UNK sentences.
Method Strengths and Weaknesses
Strengths
- Removes the fixed-vector bottleneck with per-step source conditioning.
- Large gain over RNNencdec: 28.45 vs. 17.82 BLEU.
- Long-sentence BLEU degrades much more slowly.
- Alignment weights expose interpretable source–target correspondences.
Weaknesses
- Still trails Moses on full BLEU: 28.45 vs. 30.64.
- Uses a 30k shortlist, so unknown words remain a failure mode.
- Alignment scoring scales with source and target lengths.
- Evaluation focuses on English→French only.
Suggestions from the authors
- Extend the model to larger vocabularies and better unknown-word handling.
- Apply the architecture to speech recognition and other sequence transduction tasks.
- Explore alternatives to the feedforward alignment model.
- Improve training and decoding efficiency on long sentences.
Links
Prior Papers
- @sutskeverSeq2Seq2014 — establishes the fixed-vector encoder–decoder baseline that attention replaces.
- @choGRU2014 — provides the gated recurrent encoder–decoder formulation used as the immediate baseline.
Further Papers
- @vaswaniAttentionAllNeed2017 — generalizes soft alignment into fully attention-based sequence transduction without recurrence.