Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Problem
Framing
Transfer learning for NLP had fragmented across incompatible objectives, architectures, and task formats, so comparisons were confounded. T5 closes this by casting every task as text-to-text and scaling one encoder-decoder recipe to strong results, including GLUE and SuperGLUE .
Currently Used Methods
Foundational
- @vaswaniAttentionAllNeed2017 — Transformer sequence transduction with self-attention.
- Limitation in context: no unified transfer-learning objective or task format.
- @radfordGPT2018 — decoder-only language-model pre-training for generative transfer.
- Limitation in context: awkward for classification, regression, and span extraction.
- @devlinBERT2018 — masked denoising pre-training with bidirectional context.
- Limitation in context: objective is not naturally text generation.
- @petersELMo2018 — contextual representations from language-model pre-training.
- Limitation in context: feature extraction underuses end-to-end fine-tuning.
- XLNet: Generalized Autoregressive Pretraining for Language Understanding — permutation language modeling for bidirectional context.
- Limitation in context: objective changes alone do not unify task formatting.
Proposed Method
Architecture
T5 uses a standard encoder-decoder Transformer with shared input/output embeddings, relative position embeddings, ReLU feed-forward blocks, and dropout . The baseline uses 12 encoder layers, 12 decoder layers, , , and 12 heads.
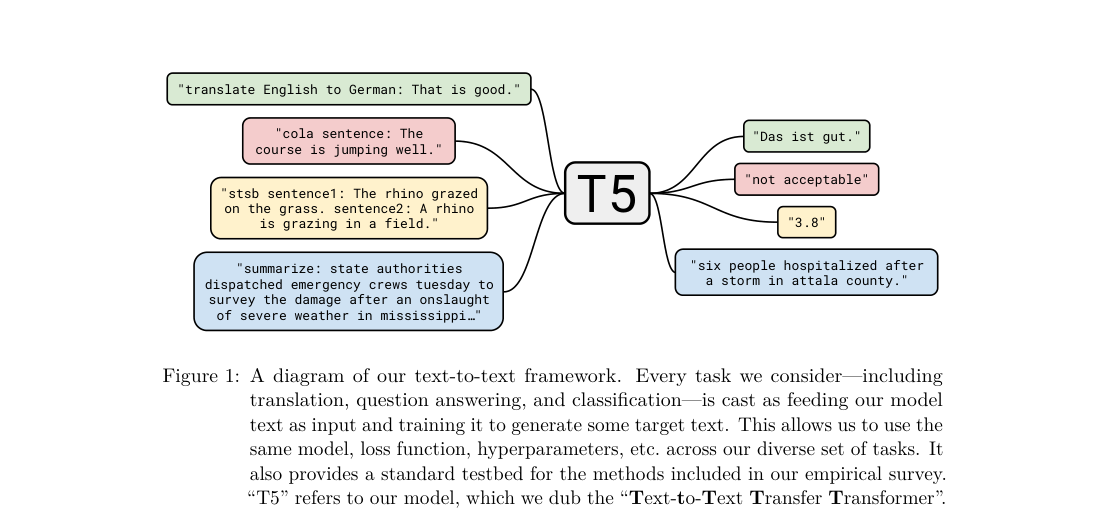
Loss / Objective
All tasks use teacher-forced maximum likelihood over target text.
Algorithm
Pre-training uses span corruption: corrupted spans in are replaced by sentinel tokens, and the target concatenates the missing spans.
Training Procedure
- Baseline: 12 encoder layers, 12 decoder layers, , , 12 heads.
- Baseline size: M parameters.
- Dropout: .
- Vocabulary: 32k SentencePiece tokens.
- Optimizer: AdaFactor.
- Schedule: inverse square root, warmup steps.
- Baseline pre-training: length 512, batch tokens, steps.
- Final pre-training: steps, batch sequences of length 512.
- Final denoising: corrupt 15% of tokens, mean span length 3.
- Model sizes: 60M, 220M, 770M, 2.8B, 11B.
- Decoding for CNN/DM and WMT: beam width 4, length penalty .
Evaluation
Datasets
- Pre-training: C4.
- Benchmarks: GLUE, SuperGLUE, CNN/Daily Mail, SQuAD, WMT En-De, WMT En-Fr, WMT En-Ro.
Metrics
- GLUE: benchmark average and task scores.
- SuperGLUE: benchmark average.
- CNN/Daily Mail: ROUGE-2.
- SQuAD: F1.
- WMT: BLEU.
Headline results
- GLUE test: .
- SuperGLUE test: .
- CNN/Daily Mail test: ROUGE-2 .
- SQuAD test: F1 .
- WMT En-De / En-Fr / En-Ro test: BLEU .
Ablations
- Objective: span corruption slightly beats i.i.d. denoising and uses shorter targets.
- Data quality: C4 beats less filtered Common Crawl variants on average.
- Data repetition: repeating small unlabeled corpora hurts transfer.
- Scale: bigger models improve more than only longer training or larger batches.
Method Strengths and Weaknesses
Strengths
- One interface covers translation, QA, summarization, classification, and regression.
- Encoder-decoder transfer beats strong encoder-only and decoder-only alternatives in the study.
- Ablations isolate objective, data, architecture, and scale effects.
- T5-11B reaches GLUE and SuperGLUE.
Weaknesses
- Best results depend on 11B parameters and about pre-training tokens.
- Study centers on English tasks despite web-scale pre-training.
- Unified text outputs can add decoding overhead for simple classification.
- Contribution is recipe synthesis and scaling, not a new backbone.
Suggestions from the authors
- Develop pre-training objectives more efficient than span denoising.
- Extend the framework to multilingual transfer.
- Reduce fine-tuning and inference cost for large models.
- Use domain-specific unlabeled data without harmful repetition.
Links
Prior Papers
- @vaswaniAttentionAllNeed2017 — supplies the encoder-decoder Transformer backbone that T5 keeps.
- @devlinBERT2018 — provides the denoising pre-training baseline that T5 reformulates as text-to-text.
- @radfordGPT2018 — motivates generative transfer with language-model pre-training.
- @petersELMo2018 — earlier transfer-learning baseline for contextual representations.
Further Papers
- @brownGPT3_2020 — extends large-scale transfer learning through prompt-based task conditioning.
- @hoffmannChinchilla2022 — sharpens the scaling-efficiency questions that T5 raises.
- @ouyangInstructGPT2022 — follows the text-in, text-out paradigm for instruction-following language models.
- @alayracFlamingo2022 — extends prompted sequence modeling to multimodal few-shot transfer.