Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Problem
Framing
Standard few-shot prompting underuses large language models on multi-step reasoning. The paper closes this gap by inserting natural-language intermediate steps into exemplars. On GSM8K, PaLM 540B rises from 18% to 57% accuracy.
Currently Used Methods
Foundational
- @brownGPT3_2020 — few-shot prompting with input–output exemplars.
- Limitation in context: weak on multi-step reasoning, even at large scale.
- Training from scratch for natural-language rationales — models learn to emit intermediate reasoning traces.
- Limitation in context: needs rationale supervision, not prompt-only adaptation.
- Finetuned GPT-3 with verifier — supervised math reasoning plus learned checking.
- Limitation in context: requires labeled solutions and extra task-specific machinery.
- Neuro-symbolic reasoning methods — use formal intermediate representations for reasoning.
- Limitation in context: less flexible than plain-language prompting on off-the-shelf LMs.
Proposed Method
Architecture
The method changes the prompt, not the model. Each exemplar is a triple , and decoding stays autoregressive. The page figure shows side-by-side prompt formats: direct answer prediction versus rationale-then-answer prompting.

Loss / Objective
The paper keeps the pretrained next-token objective over the prompted sequence.
Sampling Rule
Inference generates a rationale followed by an answer under the CoT prompt.
Training Procedure
- No parameter updates.
- Eight handwritten CoT exemplars for most tasks.
- Four exemplars for AQuA.
- Greedy decoding for main results.
- LaMDA results averaged over 5 exemplar-order seeds.
Evaluation
Datasets
- Arithmetic: GSM8K, SVAMP, ASDiv, AQuA, MAWPS.
- Commonsense: CSQA, StrategyQA, Date Understanding, Sports Understanding, SayCan.
- Symbolic: Last Letter Concatenation, Coin Flip.
Metrics
- Accuracy (%).
- Solve rate (%) in summary plots.
Headline results
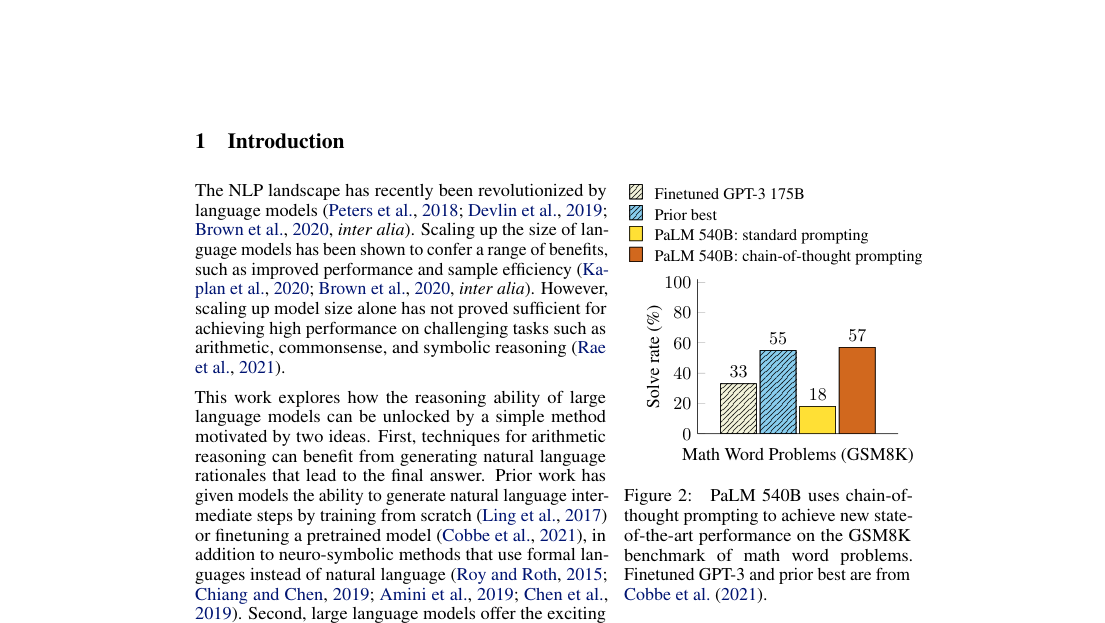
- GSM8K, PaLM 540B: 57% CoT vs 18% standard.
- GSM8K, summary bar chart: 57% CoT vs 55% prior best vs 33% finetuned GPT-3.
- Arithmetic, PaLM 540B: new state of the art on GSM8K, SVAMP, and MAWPS.
- Commonsense and symbolic tasks: gains appear only at sufficient model scale.
- Symbolic OOD length generalization: CoT improves extrapolation.
Ablations
- Model scale: CoT helps only after models become large enough.
- Equation-only prompting: beats standard prompting, but trails full natural-language CoT.
- Annotator variation: different rationale writers change scores, but CoT still wins.
- Exemplar wording and order: prompt engineering matters, yet CoT keeps a large margin.
Method Strengths and Weaknesses
Strengths
- No finetuning; only exemplar format changes.
- GSM8K gain is large: 18% to 57% on PaLM 540B.
- One prompt pattern transfers across arithmetic, commonsense, and symbolic tasks.
- Generated rationales expose intermediate steps for debugging.
Weaknesses
- Gains are strongly scale-dependent.
- Performance depends on handcrafted rationale exemplars.
- Prompt wording and exemplar order still affect results.
- Rationales can sound plausible without guaranteeing faithful reasoning.
Suggestions from the authors
- Study why CoT gains emerge only at large model scale.
- Test whether generated chains are faithful, not just answer-correlated.
- Improve robustness to exemplar choice, wording, and annotator style.
- Extend CoT prompting to broader reasoning tasks.
Links
Prior Papers
- @brownGPT3_2020 — establishes few-shot prompting, which this paper augments with explicit intermediate reasoning.
Further Papers
- @kojimaZeroShotCoT2022 — extends the same idea by eliciting chain-of-thought without handcrafted few-shot exemplars.